
 免费 AI IDE
免费 AI IDE

scikit-learn 双聚类
可以使用sklearn.cluster.bicluster模块进行Biclustering(双聚类) 。 双聚类算法同时对数据矩阵的行和列进行聚类。而这些行列的聚类称之为双向簇(biclusters)。每一次聚类都会基于原始数据矩阵确定一个子矩阵, 并且这些子矩阵具有一些需要的属性。
例如, 给定一个矩阵 (10, 10) 的矩阵 , 如果对其中 3 行 2 列进行双向聚类,就可以诱导出一个子矩阵 (3, 2)。
>>> import numpy as np
>>> data = np.arange(100).reshape(10, 10)
>>> rows = np.array([0, 2, 3])[:, np.newaxis]
>>> columns = np.array([1, 2])
>>> data[rows, columns]
array([[ 1, 2],
[21, 22],
[31, 32]])
出于可视化目的,给定一个双向簇,可以重新排列数据矩阵的行和列以使双向簇是连续的。
不同的双向聚类算法在如何定义双向簇方面有所不同,一些常见的类型包括:
常量, 常量行或常量列 异常高或低的值 低方差的子矩阵 相关联的行或列
算法采用不同的方式给双向簇分配行列,这导致了不同的双向聚类结构。当将行和列划分为区块时,将出现块对角或棋盘结构。
如果每一行和每一列恰好属于一个二元组,则重新排列数据矩阵的行和列将显示对角线上的二元组。这是此结构的示例,此结构的双向簇具有比其他行列更高的平均值:
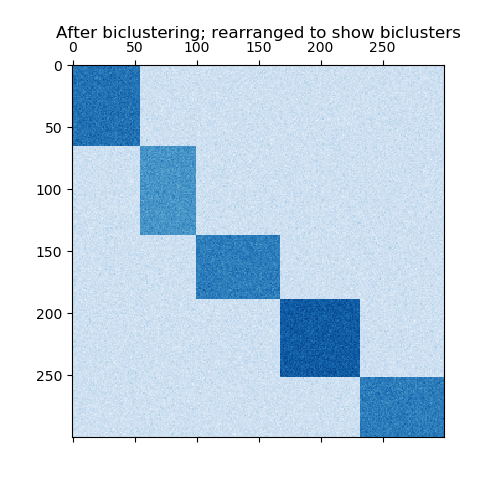
 通过分隔行和列形成的双向簇的示例
通过分隔行和列形成的双向簇的示例
在棋盘结构的例子中,每一行属于所有的列簇, 每一列属于所有的行簇。下面是这种结构的一个例子,每个双向簇内的值差异较小:
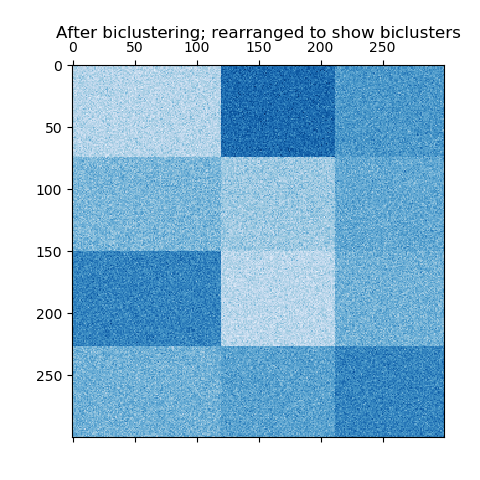
 棋盘格状双簇的示例
棋盘格状双簇的示例
在对模型进行拟合之后,可以在 rows_ 和 columns_ 属性中找到行簇和列簇的归属信息。rows_[i] 是一个二元向量,其中非零项对应于属于双向簇i 的行。 columns_[i] 就表示属于双向簇 i 的列。
一些模型还具有 row_labels_ 和 column_labels_ 属性。这些模型划分行和列,例如在块对角或者棋盘双向簇结构。
注意 双向聚类在不同的领域有很多其他名称,包括 co-clustering, two-mode clustering, two-way clustering, block clustering, coupled two-way clustering 等等。一些算法的名称,比如 Spectral Co-Clustering algorithm, 反映了这些替代名称。
2.4.1. 联合谱聚类
SpectralCoclustering(联合谱聚类)算法可以找到比对应的其他行和列的值更高的双向簇(biclusters)。每一行和每一列都只对应一个双向簇, 因此重新分配行和列以使分区相邻,显示对角线上的高值:
注意:该算法将输入数据矩阵看做成二分图:矩阵的行和列对应于两组顶点,每个条目对应于行和列之间的一条边,该算法近似于此图的归一化割,以找到重子图。
2.4.1.1. 数学公式
可以 通常这意味着直接使用拉普拉斯矩阵。 如果原始数据矩阵 的形状为 , 则对应的二分图的拉普拉斯矩阵具有形状 (m+n)×(m+n)。 但是, 在这种情况下, 直接使用 , 因为它更小,更有效。
输入矩阵 预处理如下:
为对角线矩阵,其中元素 等于 , 是对角矩阵,其中 等于 ,
奇异值分解, 产生了 行列的分区,左边奇异向量的子集给予行分区,右边的奇异向量的子集给予列分区。
奇异向量 从第二个开始,奇异向量提供了所需的分区信息,它们用于形成矩阵 :
的列是 类似于 。
然后 的所有行通过k-means进行聚类. 第一个n_rows 标签提供行分区信息, 剩下的 n_columns 标签提供列分区信息。
示例:
光谱共聚类算法演示: 一个简单的示例,展示了如何使用双向簇生成数据矩阵并将其应用。 用谱协聚类算法对文档进行集群化:一个在 20 个新闻组数据集中找双向簇的示例 参考文献:
Dhillon, Inderjit S, 2001. Co-clustering documents and words using bipartite spectral graph partitioning.
2.4.2. 光谱双聚类
该SpectralBiclustering算法假定输入数据矩阵具有隐藏的棋盘结构。可以对具有这种结构的矩阵的行和列进行分区,例如,如果有两个行分区和三个列分区,则每行将属于三个bicluster,而每列将属于两个bicluster。
该算法对矩阵的行和列进行划分,以使相应的块状不变的棋盘矩阵可以很好地逼近原始矩阵。
2.4.2.1. 数学表示
先归一化输入矩阵 ,使得矩阵的棋盘模式更明显。有三种可能的方法:
独立的行列归一化,如联合谱聚类中所示。此方法使行总和为常量,而列总和为另一个的常量。 Bistochastization: 重复行和列归一化直到收敛。此方法使行和列的总和为相同的常数。 对数归一化: 计算数据矩阵的对数 。列均值是 ,行均值是 ,是 的整体平均。根据公式计算出最终矩阵:
归一化之后,就像在联合谱聚类算法中一样,计算前几个奇异矢量。
如果使用对数归一化,则所有奇异向量都是有意义的。但是, 如果使用独立的归一化或双歧化, 则第一个奇异矢量 和 被丟弃。从现在开始,“第一个“奇异向量指的是 和 对数归一化的情况除外。
给定这些奇异向量,按照分段常数向量的最佳近似程度进行排序。使用一维 k-means 找到每个向量的近似值,并使用欧氏距离进行评分。选择最佳左右奇异向量的一些子集。接下来, 将数据投影到奇异向量的最佳子集并进行聚类。
例如,如果计算 个奇异向量,因为 $q
示例:
谱协聚类算法的一个示例: 一个简单的示例,展示如何生成棋盘矩阵并对它进行双向聚类。 参考资料:
Kluger, Yuval, et. al., 2003. Spectral biclustering of microarray data: coclustering genes and conditions.
2.4.3. Biclustering 评价
评估双聚类结果有两种方法:内部和外部。内部度量,如聚类稳定性, 只依赖于数据和结果本身。目前scikit-learn还没有内部的双向簇度量。外部度量是指外部信息来源,例如真实解。当处理真实数据时,真实解通常是未知的,但是,双聚类人工数据可能有助于精确地评估算法,因为真实解是已知的。
为了将一组已发现的双向簇与一组真实的双向簇行比较,需要两种相似性度量:一种是单个双向簇的相似性度量,另一种是将这些个体相似度整合到整体得分中的方法。
为了比较单个双向簇,采用了几种方法。现在,目前只执行 Jaccard 索引:
其中A和B是双向簇, |A∩B| 是交叉点的元素数量。
Jaccard 索引达到最小值0,当biclusters完全不同时,Jaccard指数最小值为0;当biclusters完全相同时,Jaccard指数最大值为1。
已经开发了几种方法来比较两个双向簇的集合。目前,只有consensus_score(Hochreiter等人,2010)可用:
使用Jaccard索引或类似度量, 为每个集合中的双向簇对计算簇之间的相似性。 以一对一的方式将双向簇从一个集合分配给另一个集合,以最大化他们的相似性之和。使用匈牙利算法(Hungarian algorithm)执行此步骤。 最终的相似度之和除以较大集合的大小。
当所有双向簇对都完全不相似时,将出现最低共识分数0。当两个双向簇集合相同时,出现最高分数为1。
参考文献:
Hochreiter, Bodenhofer, et. al., 2010. FABIA: factor analysis for bicluster acquisition.


更多建议: