
 免费 AI IDE
免费 AI IDE

scikit-learn 神经网络模型(无监督)
2.9.1. 受限波尔兹曼机
受限玻尔兹曼机(RBM)是一种基于概率模型的无监督非线性特征学习器。当馈入线性分类器(如线性支持向量机或感知机)时,用 RBM 或多层次结构的RBM提取的特征时通常会获得良好的结果。
该模型对输入的分布做出假设。目前,scikit-learn 只提供了 BernoulliRBM,它假定输入是二值的,或是 0 到 1 之间的值,每个值都编码了特定特征被激活的可能性。
RBM尝试使用特定的图形模型来最大化数据的可似然。所使用的参数学习算法(随机最大似然)可防止特征偏离输入数据,从而使它们捕获到特征有趣的规律性,但使模型对小型数据集的用处不大,通常不适用于密度估计。
该方法以初始化具有独立RBM权重的深度神经网络而广受欢迎。这种方法称为无监督预训练。


示例:
[Restricted Boltzmann Machine features for digit classification](
2.9.1.1. 图形模型和参数化
RBM 的图形模型是一个全连接的二分图。
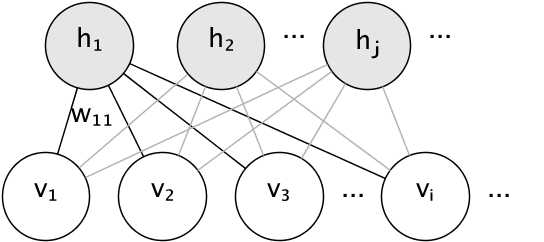
 节点是随机变量,其状态取决于它们连接到的其他节点的状态。因此,通过连接的权重以及每个可见和隐藏单元的一个偏置项(截距)对模型进行参数化,为简单起见,图像中将其省略。
节点是随机变量,其状态取决于它们连接到的其他节点的状态。因此,通过连接的权重以及每个可见和隐藏单元的一个偏置项(截距)对模型进行参数化,为简单起见,图像中将其省略。
用能量函数衡量联合概率分布的质量:
在上面的公式中 b 和 c分别是可见层和隐藏层的截距向量。该模型的联合概率是根据能量定义的:
“限制”是指模型的二分图结构,它禁止隐藏单元或可见单元之间的直接交互。这意味着假定以下条件独立:
二分图结构允许使用高效的块Gibbs采样进行推断。
2.9.1.2. 伯努利受限玻尔兹曼机
在 BernoulliRBM 中,所有单位都是二进制随机单元。这意味着输入的数据应该是二值,或者是介于 0 和 1 之间的实数值,其表示可见单元将打开或关闭的可能性。这对于字符识别是一个很好的模型,因为我们感兴趣的是哪些像素处于活动状态,哪些像素未处于活动状态。 对于自然场景的图像,由于背景、深度和相邻像素趋向于取相同的值,它不再适合。
每个单位的条件概率分布由其接收的输入的 logistic sigmoid函数给出:
其中 是 logistic sigmoid函数:
2.9.1.3. 随机最大似然学习
在 BernoulliRBM 函数中实现的训练算法被称为随机最大似然(SML)或持续对比发散(PCD)。由于数据的似然函数的形式,直接优化最大似然是不可行的:
为简单起见,上面的公式是针对单个训练样本编写的相对于权重的梯度由与上述相对应的两项构成。对应它们各自的符号,通常被称为正梯度和负梯度。在该实施方式中,梯度是在样本的小批量上估计的。
在最大化对数似然度的过程中,正梯度使得模型更倾向于与观测到的训练数据相容的隐藏状态。由于RBMs 的二分体结构可以使它被高效地计算。然而,负梯度是棘手的。它的目标是降低模型偏好的联合状态的能量,从而使其与数据保持一致。它可以使用马尔可夫链蒙特卡罗来通过Gibbs采样粗略估计,它通过迭代地对每个 和 进行交互采样,直到链混合。以这种方式产生的样本有时被称为幻想粒子。这是低效的,并且很难确定马可夫链是否混合。
对比发散方法建议在经过少量迭代后停止链,迭代数 通常是 1。该方法速度快、方差小,但样本远离模型分布。
持续对比发散解决了这个问题。在 PCD 中,我们保留了多个链(幻想粒子)来在每个权重更新之后更新 个Gibbs采样步骤,而不是每次需要梯度时都启动一个新的链,并且只执行一个吉比斯采样步骤。这使得粒子能更彻底地探索空间。
参考文献;
“A fast learning algorithm for deep belief nets” G. Hinton, S. Osindero, Y.-W. Teh, 2006 “Training Restricted Boltzmann Machines using Approximations to the Likelihood Gradient” T. Tieleman, 2008


更多建议: