


浏览器的JavaScript引擎
浏览器通过内置的JavaScript引擎,读取网页中的代码,对其处理后运行。
JavaScript代码嵌入网页的方法
在网页中嵌入JavaScript代码有多种方法。
直接添加代码块
通过script标签,可以直接将JavaScript代码嵌入网页。
<script>
// some JavaScript code
</script>加载外部脚本
script标签也可以指定加载外部的脚本文件。
<script src="example.js"></script>如果脚本文件使用了非英语字符,还应该注明编码。
<script charset="utf-8" src="https://atts.w3cschool.cn/attachments/image/cimg/pre>
加载外部脚本和直接添加代码块,这两种方法不能混用。下面代码的console.log语句直接被忽略。
<script charset="utf-8" src="example.js">
console.log('Hello World!');
</script>
行内代码
除了上面两种方法,HTML语言允许在某些元素的事件属性和a元素的href属性中,直接写入JavaScript。
<div onclick="alert('Hello')"></div>
<a href="javascript:alert('Hello')"></a>
这种写法将HTML代码与JavaScript代码混写在一起,非常不利于代码管理,不建议使用。
外部脚本的加载
网页底部加载
正常的网页加载流程是这样的。
- 浏览器一边下载HTML网页,一边开始解析
- 解析过程中,发现script标签
- 暂停解析,下载script标签中的外部脚本
- 下载完成,执行脚本
- 恢复往下解析HTML网页
也就是说,加载外部脚本时,浏览器会暂停页面渲染,等待脚本下载并执行完成后,再继续渲染。如果加载时间很长(比如一直无法完成下载),就会造成网页长时间失去响应,浏览器就会呈现“假死”状态,失去响应,这被称为“阻塞效应”。这样设计是因为JavaScript代码可能会修改页面,所以必须等它执行完才能继续渲染。为了避免这种情况,较好的做法是将script标签都放在页面底部,而不是头部。当然,如果某些脚本代码非常重要,一定要放在页面头部的话,最好直接将代码嵌入页面,而不是连接外部脚本文件,这样能缩短加载时间。
将脚本文件都放在网页尾部加载,还有一个好处。在DOM结构生成之前就调用DOM,JavaScript会报错,如果脚本都在网页尾部加载,就不存在这个问题,因为这时DOM肯定已经生成了。
<head>
<script>
console.log(document.body.innerHTML);
</script>
</head>
上面代码执行时会报错,因为此时body元素还未生成。
一种解决方法是设定DOMContentLoaded事件的回调函数。
<head>
<script>
document.addEventListener("DOMContentLoaded", function(event) {
console.log(document.body.innerHTML);
});
</script>
</head>
另一种解决方法是,使用script标签的onload属性。当script标签指定的外部脚本文件下载和解析完成,会触发一个load事件,可以为这个事件指定回调函数。
<script src="jquery.min.js" onload="console.log(document.body.innerHTML)">
</script>
但是,如果将脚本放在页面底部,就可以完全按照正常的方式写,上面两种方式都不需要。
<body>
<!-- 其他代码 -->
<script>
console.log(document.body.innerHTML);
</script>
</body>
多个脚本的加载
如果有多个script标签,比如下面这样。
<script src="https://atts.w3cschool.cn/attachments/image/cimg/script>
<script src="2.js"></script>
浏览器会同时平行下载1.js和2.js,但是执行时会保证先执行1.js,然后再执行2.js,即使后者先下载完成,也是如此。也就是说,脚本的执行顺序由它们在页面中的出现顺序决定,这是为了保证脚本之间的依赖关系不受到破坏。
当然,加载这两个脚本都会产生“阻塞效应”,必须等到它们都加载完成,浏览器才会继续页面渲染。
此外,对于来自同一个域名的资源,比如脚本文件、样式表文件、图片文件等,浏览器一般最多同时下载六个。如果是来自不同域名的资源,就没有这个限制。所以,通常把静态文件放在不同的域名之下,以加快下载速度。
defer属性
为了解决脚本文件下载阻塞网页渲染的问题,一个方法是加入defer属性。
<script src="https://atts.w3cschool.cn/attachments/image/cimg/script>
<script src="2.js" defer></script>
defer属性的运行过程是这样的。
- 浏览器开始解析HTML网页
- 解析过程中,发现带有defer属性的script标签
- 浏览器继续往下解析HTML网页,同时并行下载script标签中的外部脚本
- 浏览器完成解析HTML网页,此时再执行下载的脚本
有了defer属性,浏览器下载脚本文件的时候,不会阻塞页面渲染。下载的脚本文件在DOMContentLoaded事件触发前执行(即刚刚读取完标签),而且可以保证执行顺序就是它们在页面上出现的顺序。但是,浏览器对这个属性的支持不够理想,IE(<=9)还有一个bug,无法保证2.js一定在1.js之后执行。如果需要支持老版本的IE,且脚本之间有依赖关系,建议不要使用defer属性。
对于内置而不是连接外部脚本的script标签,以及动态生成的script标签,defer属性不起作用。
async属性
解决“阻塞效应”的另一个方法是加入async属性。
<script src="https://atts.w3cschool.cn/attachments/image/cimg/script>
<script src="2.js" async></script>
async属性的运行过程是这样的。
- 浏览器开始解析HTML网页
- 解析过程中,发现带有async属性的script标签
- 浏览器继续往下解析HTML网页,同时并行下载script标签中的外部脚本
- 脚本下载完成,浏览器暂停解析HTML网页,开始执行下载的脚本
- 脚本执行完毕,浏览器恢复解析HTML网页
async属性可以保证脚本下载的同时,浏览器继续渲染。需要注意的是,一旦采用这个属性,就无法保证脚本的执行顺序。哪个脚本先下载结束,就先执行那个脚本。使用async属性的脚本文件中,不应该使用document.write方法。IE 10支持async属性,低于这个版本的IE都不支持。
defer属性和async属性到底应该使用哪一个?一般来说,如果脚本之间没有依赖关系,就使用async属性,如果脚本之间有依赖关系,就使用defer属性。如果同时使用async和defer属性,后者不起作用,浏览器行为由async属性决定。
脚本的动态嵌入
除了用静态的script标签,还可以动态嵌入script标签。
['1.js', '2.js'].forEach(function(src) {
var script = document.createElement('script');
script.src = src;
document.head.appendChild(script);
});
这种方法的好处是,动态生成的script标签不会阻塞页面渲染,也就不会造成浏览器假死。但是问题在于,这种方法无法保证脚本的执行顺序,哪个脚本文件先下载完成,就先执行哪个。
如果想避免这个问题,可以设置async属性为false。
['1.js', '2.js'].forEach(function(src) {
var script = document.createElement('script');
script.src = src;
script.async = false;
document.head.appendChild(script);
});
上面的代码依然不会阻塞页面渲染,而且可以保证2.js在1.js后面执行。不过需要注意的是,在这段代码后面加载的脚本文件,会因此都等待2.js执行完成后再执行。
我们可以把上面的写法,封装成一个函数。
(function() {
var script,
scripts = document.getElementsByTagName('script')[0];
function load(url) {
script = document.createElement('script');
script.async = true;
script.src = url;
scripts.parentNode.insertBefore(script, scripts);
}
load('//apis.google.com/js/plusone.js');
load('//platform.twitter.com/widgets.js');
load('//s.thirdpartywidget.com/widget.js');
}());
此外,动态嵌入还有一个地方需要注意。动态嵌入必须等待CSS文件加载完成后,才会去下载外部脚本文件。静态加载就不存在这个问题,script标签指定的外部脚本文件,都是与CSS文件同时并发下载的。
加载使用的协议
如果不指定协议,浏览器默认采用HTTP协议下载。
<script src="https://atts.w3cschool.cn/attachments/image/cimg/pre>
上面的example.js默认就是采用http协议下载,如果要采用HTTPs协议下载,必需写明(假定服务器支持)。
<script src="https://atts.w3cschool.cn/attachments/image/cimg/example.js"></script>
但是有时我们会希望,根据页面本身的协议来决定加载协议,这时可以采用下面的写法。
<script src="https://atts.w3cschool.cn/attachments/image/cimg/example.js"></script>
JavaScript虚拟机
JavaScript是一种解释型语言,也就是说,它不需要编译,可以由解释器实时运行。这样的好处是运行和修改都比较方便,刷新页面就可以重新解释;缺点是每次运行都要调用解释器,系统开销较大,运行速度慢于编译型语言。为了提高运行速度,目前的浏览器都将JavaScript进行一定程度的编译,生成类似字节码(bytecode)的中间代码,以提高运行速度。
早期,浏览器内部对JavaScript的处理过程如下:
- 读取代码,进行词法分析(Lexical analysis),将代码分解成词元(token)。
- 对词元进行语法分析(parsing),将代码整理成“语法树”(syntax tree)。
- 使用“翻译器”(translator),将代码转为字节码(bytecode)。
- 使用“字节码解释器”(bytecode interpreter),将字节码转为机器码。
逐行解释将字节码转为机器码,是很低效的。为了提高运行速度,现代浏览器改为采用“即时编译”(Just In Time compiler,缩写JIT),即字节码只在运行时编译,用到哪一行就编译哪一行,并且把编译结果缓存(inline cache)。通常,一个程序被经常用到的,只是其中一小部分代码,有了缓存的编译结果,整个程序的运行速度就会显著提升。
不同的浏览器有不同的编译策略。有的浏览器只编译最经常用到的部分,比如循环的部分;有的浏览器索性省略了字节码的翻译步骤,直接编译成机器码,比如chrome浏览器的V8引擎。
字节码不能直接运行,而是运行在一个虚拟机(Virtual Machine)之上,一般也把虚拟机称为JavaScript引擎。因为JavaScript运行时未必有字节码,所以JavaScript虚拟机并不完全基于字节码,而是部分基于源码,即只要有可能,就通过JIT(just in time)编译器直接把源码编译成机器码运行,省略字节码步骤。这一点与其他采用虚拟机(比如Java)的语言不尽相同。这样做的目的,是为了尽可能地优化代码、提高性能。下面是目前最常见的一些JavaScript虚拟机:
- Chakra(Microsoft](http://en.wikipedia.org/wiki/Chakra_(JScript_engine%5C))(Microsoft) Internet Explorer)
- Nitro/JavaScript Core (Safari)
- Carakan (Opera)
- SpiderMonkey (Firefox)
- V8) (Chrome, Chromium)
单线程模型
JavaScript采用单线程模型,也就是说,所有的任务都在一个线程里运行。这意味着,一次只能运行一个任务,其他任务都必须在后面排队等待。
JavaScript之所以采用单线程,而不是多线程,跟历史有关系。JavaScript从诞生起就是单线程,原因是不想让浏览器变得太复杂,因为多线程需要共享资源、且有可能修改彼此的运行结果,对于一种网页脚本语言来说,这就太复杂了。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变。
为了利用多核CPU的计算能力,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质。
单线程模型带来了一些问题,主要是新的任务被加在队列的尾部,只有前面的所有任务运行结束,才会轮到它执行。如果有一个任务特别耗时,后面的任务都会停在那里等待,造成浏览器失去响应,又称“假死”。为了避免“假死”,当某个操作在一定时间后仍无法结束,浏览器就会跳出提示框,询问用户是否要强行停止脚本运行。
如果排队是因为计算量大,CPU忙不过来,倒也算了,但是很多时候CPU是闲着的,因为IO设备(输入输出设备)很慢(比如Ajax操作从网络读取数据),不得不等着结果出来,再往下执行。JavaScript语言的设计者意识到,这时CPU完全可以不管IO设备,挂起处于等待中的任务,先运行排在后面的任务。等到IO设备返回了结果,再回过头,把挂起的任务继续执行下去。这种机制就是JavaScript内部采用的Event Loop。
Event Loop
所谓Event Loop,指的是一种内部循环,用来排列和处理事件,以及执行函数。Wikipedia的定义是:“Event Loop是一个程序结构,用于等待和发送消息和事件。(a programming construct that waits for and dispatches events or messages in a program.)”
所有任务可以分成两种,一种是同步任务(synchronous),另一种是异步任务(asynchronous)。同步任务指的是,在主线程上排队执行的任务,只有前一个任务执行完毕,才能执行后一个任务;异步任务指的是,不进入主线程、而进入“任务队列”(task queue)的任务,只有“任务队列”通知主线程,某个异步任务可以执行了,该任务才会进入主线程执行。
以Ajax操作为例,它可以当作同步任务处理,也可以当作异步任务处理,由开发者决定。如果是同步任务,主线程就等着Ajax操作返回结果,再往下执行;如果是异步任务,该任务直接进入“任务队列”,主线程跳过Ajax操作,直接往下执行,等到Ajax操作有了结果,主线程再执行对应的回调函数。
想要理解Event Loop,就要从程序的运行模式讲起。运行以后的程序叫做"进程"(process),一般情况下,一个进程一次只能执行一个任务。如果有很多任务需要执行,不外乎三种解决方法。
-
排队。因为一个进程一次只能执行一个任务,只好等前面的任务执行完了,再执行后面的任务。
-
新建进程。使用fork命令,为每个任务新建一个进程。
- 新建线程。因为进程太耗费资源,所以如今的程序往往允许一个进程包含多个线程,由线程去完成任务。
如果某个任务很耗时,比如涉及很多I/O(输入/输出)操作,那么线程的运行大概是下面的样子。

上图的绿色部分是程序的运行时间,红色部分是等待时间。可以看到,由于I/O操作很慢,所以这个线程的大部分运行时间都在空等I/O操作的返回结果。这种运行方式称为"同步模式"(synchronous I/O)。
如果采用多线程,同时运行多个任务,那很可能就是下面这样。
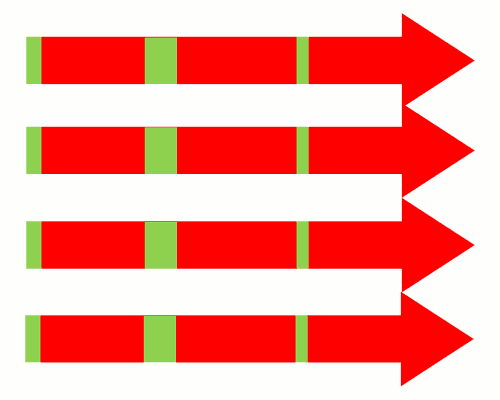
上图表明,多线程不仅占用多倍的系统资源,也闲置多倍的资源,这显然不合理。
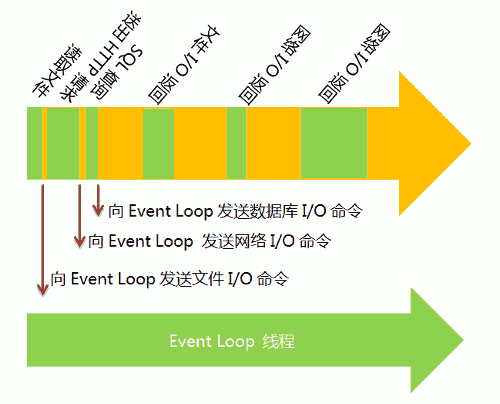
上图主线程的绿色部分,还是表示运行时间,而橙色部分表示空闲时间。每当遇到I/O的时候,主线程就让Event Loop线程去通知相应的I/O程序,然后接着往后运行,所以不存在红色的等待时间。等到I/O程序完成操作,Event Loop线程再把结果返回主线程。主线程就调用事先设定的回调函数,完成整个任务。
可以看到,由于多出了橙色的空闲时间,所以主线程得以运行更多的任务,这就提高了效率。这种运行方式称为"异步模式"(asynchronous I/O)。
这正是JavaScript语言的运行方式。单线程模型虽然对JavaScript构成了很大的限制,但也因此使它具备了其他语言不具备的优势。如果部署得好,JavaScript程序是不会出现堵塞的,这就是为什么node.js平台可以用很少的资源,应付大流量访问的原因。
任务队列
如果有大量的异步任务(实际情况就是这样),它们会在“任务队列”中注册大量的事件。这些事件排成队列,等候进入主线程。本质上,“任务队列”就是一个事件“先进先出”的数据结构。比如,点击鼠标就产生一些列事件,mousedown事件排在mouseup事件前面,mouseup事件又排在click事件的前面。
参考链接
- John Dalziel, The race for speed part 2: How JavaScript compilers work
- Jake Archibald,Deep dive into the murky waters of script loading
- Mozilla Developer Network, window.setTimeout
- Remy Sharp, Throttling function calls
- Ayman Farhat, An alternative to Javascript's evil setInterval
- Ilya Grigorik, Script-injected "async scripts" considered harmful
- Axel Rauschmayer, ECMAScript 6 promises (1/2): foundations
- Daniel Imms, async vs defer attributes
- Craig Buckler, Load Non-blocking JavaScript with HTML5 Async and Defer


更多建议: