
 免费 AI IDE
免费 AI IDE

(十八)—— 重试模式
云计算设计模式(十八)——重试模式
启用应用程序来处理预期的,暂时的失败时,它会尝试连接到由透明的重试操作了以前失败的期望,失败的原因是瞬时的服务或网络资源。这种模式可以提高应用程序的稳定性。
背景和问题
该通信的应用程序与在云中运行的元素必须是可能发生在这样的环境中的瞬时故障敏感。这些故障包括网络连接的过程中出现时,一个服务是忙碌的瞬时损失的组件和服务中,服务的临时不可用,或超时。
这些故障一般是自校正的,如果经过一个合适的延迟被重复触发一个故障的动作很可能是成功的。例如,数据库服务,它正在处理大量并发请求可以实现节流策略,暂时拒绝,直到它的工作量有所缓和任何进一步的请求。试图访问该数据库的应用程序可能无法连接,但如果它经过一个合适的延迟再次尝试它可能会成功。
解决方案
在云中,瞬时故障的情况并不少见和应用应该被设计为优雅和透明地处理它们,减少的影响,这种故障可能对应用程序正在执行业务任务。
如果一个应用程序检测到故障时,它试图将请求发送到远程服务,它可以通过使用以下策略处理失败:
- 如果故障指示故障不是瞬时的或不太成功,如果重复(例如,所造成的无效提供凭据的认证失败是不可能成功的,无论是多少次未遂),应用程序应中止操作和报告一个合适的异常。
- 如果报道的具体故障是不寻常的或罕见的,这可能是由于反常的情况,如网络数据包成为损坏,同时它被发送。在这种情况下,应用程序可以再次立即重试失败的请求,因为相同的故障是不可能被重复和请求将可能是成功的。
- 如果故障是由一种更加普遍的连接,或“忙”的失败,网络或服务可能需要在短期内同时连接问题纠正或工作的积压被清除。应用程序应该等待请求重试前一个合适的时间。
对于比较常见的短暂故障,重试期间,应选择以传播从应用程序中尽可能均匀的多个实例的请求。这可以减少繁忙的业务持续过载的可能性。如果一个应用程序的多个实例不断轰击与重试请求的服务,则可能需要该服务更长的时间来恢复。
如果请求仍然失败,应用程序可以等待进一步的时期,再次尝试。如果需要的话,这个过程可以重复而增加重试的延迟,直到请求的某一最大数目已经尝试都失败了。延迟时间可以逐步增加,或可使用的定时策略,如指数回退,取决于故障的性质和可能性,这将在这段时间内被校正。
图1示出了这种模式。如果尝试后的预定数量的请求不成功,应用程序应将故障为异常,并相应地处理它。
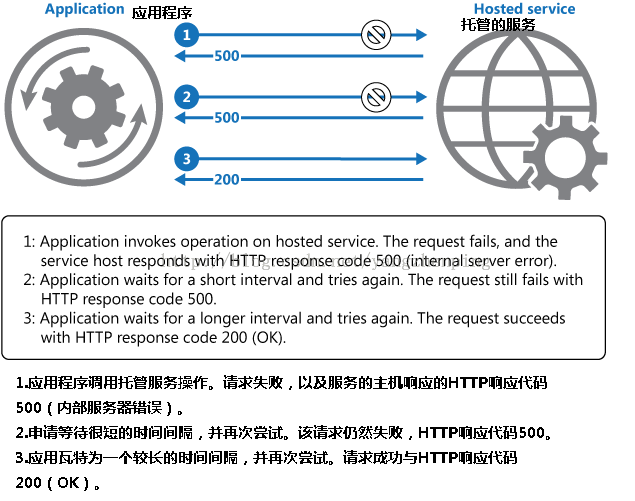
图1 - 使用重试模式中调用托管服务的操作
应用程序应该换所有试图访问远程服务,实现重试政策配套上面列出的策略之一的代码。发送到不同的服务请求会受到不同的政策,有的供应商提供封装这种方法库。这些库通常执行的政策是参数化的,而应用程序开发人员可以指定,如重试次数和重试之间的时间项的值。
在检测故障和重试失败的操作都应该记录这些故障的详细信息的应用程序的代码。这个信息可能是有用的运算符。如果一个服务被频繁报道为不可用或忙,往往是因为该服务已耗尽其资源。则可以减少与这些故障发生时通过换算出该服务的频率。例如,如果数据库服务正在不断超载,它可能是有利的分区数据库和负载分散到多个服务器。
注意: 微软 Azure 提供了重试模式的广泛支持。该模式与实践瞬态故障处理块允许应用程序通过一系列的重试策略来处理许多 Azure 服务瞬态故障。微软实体框架版本6提供了用于重新尝试数据库操作。此外,许多在 Azure Service Bus 和 Azure 存储的 API 透明地执行重试逻辑。
问题和注意事项
在决定如何实现这个模式时,您应考虑以下几点:
- 重试政策应进行调整,以满足应用和故障性质的业务需求。它可能是更好一些非关键操作失败快而不是重试几次,并影响应用程序的吞吐量。例如,在试图访问远程服务的交互式Web应用程序,这可能是更好的重试之后用重试之间只有一个短的延迟的数量较少失败,并显示一个适当的消息给用户(例如,“请稍后“),再次尝试阻止应用程序变得反应迟钝。对于批处理应用程序,它可以是更合适的,以增加重试尝试的次数与尝试之间的指数增加的延迟。
- 与尝试之间最小的延迟和大量的重试的高攻击重试的政策,可能会进一步降低正在接近运行或容量的占用。此重试策略也可能会影响应用程序的响应,如果它被不断地在尝试执行失败的操作,而不是做有用功。
- 如果后一个显著次数的重试请求仍然失败,则可能是更好的应用程序,以防止进一步的请求将要在相同的资源为一个周期,并简单地立即报告故障。当期限届满后,该应用程序可以暂时允许通过一个或多个请求,看看他们是否成功。对于这一策略的详细信息,请参阅断路器格局。
- 在由它实现了一个重试策略可能需要为幂等的应用程序调用的服务的操作。例如,发送到服务的请求可以被接收和处理成功,但是,由于瞬时故障,它可能无法发送响应,指示该处理已完成。然后在应用程序的重试逻辑可能试图重复上没有接收到所述第一请求的假定该请求。
- 一个请求到服务失败可能由于各种原因而提出不同的异常,根据故障的性质。一些例外可指示故障,可以非常迅速地得到解决,而另一些可能表明该故障持续时间更长。可能是有益的重试策略,调整基于所述异常的类型的重试尝试之间的时间。
- 考虑如何重试的操作是事务的一部分,会影响整体交易的一致性。这可能是有用的微调对于事务性操作的重试政策,最大限度地取得成功的机会,并减少需要撤消所有交易步骤。
- 确保所有重试代码是完全针对各种故障条件下进行测试。检查它不会严重影响应用程序的性能或可靠性,导致在服务和资源的过度负荷,或产生竞态条件或瓶颈。
- 实现只在一个失败的操作的全方面了解重试逻辑。例如,如果包含的重试策略任务调用另一个任务还包含一个重试策略,这个额外的重试的层可加长的延迟的处理。它可能是更好的配置的低级任务失败快速并报告失败返回调用它的任务的原因。然后这个更高级别的任务可以决定如何处理是根据它自己的策略失效。
- 记录所有的连接故障,提示了重试,使潜在的问题与该应用程序,服务或资源可以被识别是很重要的。
- 研究是最有可能发生于一个服务或资源发现,如果它们有可能是持久或终端的故障。如果是这样的话,它可能是更好地处理该故障为异常。该应用程序可以报告或记录该异常,然后试图通过调用另一个服务,持续或者(如果有一个可用的),或通过提供降级功能。关于如何检测和处理持久故障的更多信息,请参阅断路器格局。
何时使用这个模式
使用这种模式:
- 当一个应用程序可能会经历短暂的故障,因为它与远程服务进行交互,或访问远程资源。这些故障预计将是短暂的,并重复了以前没有能够成功的后续尝试的请求。
这种模式可能不适合:
- 当故障很可能是持久的,因为这可能会影响应用程序的响应性。该应用程序可以简单地是浪费时间和资源试图重复请求是最有可能失败。
- 对于处理故障是不因瞬时故障,如在应用程序的业务逻辑引起错误的内部的异常。
- 作为一种替代解决系统中的可扩展性问题。如果一个应用程序有频繁的“忙”的故障,这是通常指示被访问的服务或资源应相应加大。
例子
本实施例说明的重试模式的实现。该 OperationWithBasicRetryAsync 方法,如下所示,通过 TransientOperationAsync 方法异步调用外部服务(该方法的细节将特定于服务,并从样本代码被省略)。
private int retryCount = 3;
...
public async Task OperationWithBasicRetryAsync()
{
int currentRetry = 0;
for (; ;)
{
try
{
// Calling external service.
await TransientOperationAsync();
// Return or break.
break;
}
catch (Exception ex)
{
Trace.TraceError("Operation Exception");
currentRetry++;
// Check if the exception thrown was a transient exception
// based on the logic in the error detection strategy.
// Determine whether to retry the operation, as well as how
// long to wait, based on the retry strategy.
if (currentRetry > this.retryCount || !IsTransient(ex))
{
// If this is not a transient error
// or we should not retry re-throw the exception.
throw;
}
}
// Wait to retry the operation.
// Consider calculating an exponential delay here and
// using a strategy best suited for the operation and fault.
Await.Task.Delay();
}
}
// Async method that wraps a call to a remote service (details not shown).
private async Task TransientOperationAsync()
{
...
}调用此方法的声明被包裹在一个循环一个 try/ catch 块中封装。如果调用 TransientOperationAsync 方法成功,没有抛出异常的 for 循环退出。如果 TransientOperationAsync 方法失败,catch 块检查为失败的原因,并且如果它被认为是一个瞬时错误代码等待一个短暂的延时,然后重试该操作。
在 for 循环还跟踪该操作已经尝试的次数,并且如果代码失败三次异常被认为是更持久。如果该异常是不是暂时的,或者是长久的,catch 处理抛出的异常。此异常退出 for 循环,应捕获调用该OperationWithBasicRetryAsync 方法的代码。
该 IsTransient 方法,如下所示,检查是否有特定的一组是相关的,其中所述代码运行的环境的异常。一过异常的定义可以根据被访问的资源,并在其上执行的操作环境的不同而不同。
private bool IsTransient(Exception ex)
{
// Determine if the exception is transient.
// In some cases this may be as simple as checking the exception type, in other
// cases it may be necessary to inspect other properties of the exception.
if (ex is OperationTransientException)
return true;
var webException = ex as WebException;
if (webException != null)
{
// If the web exception contains one of the following status values
// it may be transient.
return new[] {WebExceptionStatus.ConnectionClosed,
WebExceptionStatus.Timeout,
WebExceptionStatus.RequestCanceled }.
Contains(webException.Status);
}
// Additional exception checking logic goes here.
return false;
}

更多建议: