
 免费 AI IDE
免费 AI IDE

(十二)—— 索引表模式
云计算设计模式(十二)——索引表模式
创建索引过的被查询条件经常被引用的数据存储等领域。这种模式可以通过允许应用程序更快速地定位数据来从数据存储中检索提高查询性能。
背景和问题
许多数据存储通过使用主键组织为实体的集合的数据。应用程序可以使用此键来查找和检索数据。图 1 显示了一个数据存储区保持顾客的信息的例子。主键是客户 ID。
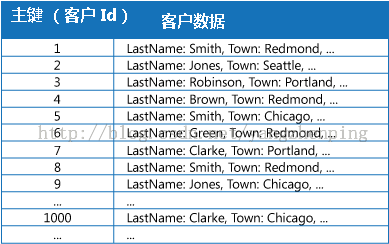
图1 - 按主键组织的客户信息(客户ID)
而主键是该取基于该关键字的值的数据的查询宝贵的,应用程序可能不能够使用主键是否需要基于其它字段来检索数据。在顾客例如,应用程序不能使用该客户ID主键来检索客户,如果它通过指定引用的一些其他属性的值,如在其中客户位于镇标准查询数据完全。要执行一个查询,如这可能需要申请获取并检查每一个客户的记录,这可能是一个缓慢的过程。
许多关系数据库管理系统支持二级索引。一种二次指数是由一个或多个非主(辅助)键领域举办一个单独的数据结构,它表示,其中每个索引值的数据被存储。在一第二索引的项目通常排序方法的第二个键的值,使数据的快速查找。这些指标通常是由数据库管理系统自动进行维护。
由于需要支持您的应用程序执行不同的查询,您可以创建任意多个二级指标。例如,在一个关系数据库中凡客ID是主键的表的客户,也可能是有益的补充辅助指数在镇域如果应用程序频繁查找的客户在其居住的小镇。
然而,尽管二级指标是关系型系统的共同特征,使用云应用大部分NoSQL数据存储不提供同等的功能。
解决方案
如果数据存储不支持二级索引,你可以通过创建自己的索引表手动效仿他们。索引表由指定的键组织数据。三种策略通常用于构建一个索引表,这取决于所需要的二次索引的数目和该应用程序执行的查询的性质:
重复数据的每个索引表中,而是由不同的密钥(完全非规范化)组织它。图2显示了索引表的组织包括城市和姓氏相同的客户信息:
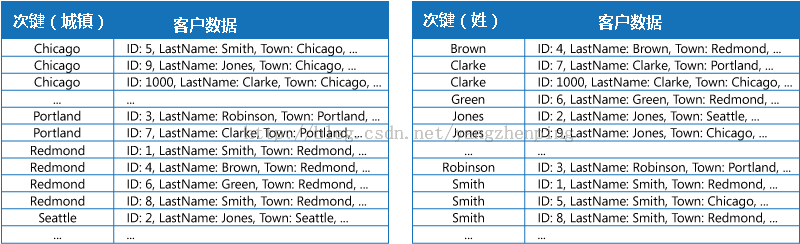
图2 - 索引表执行二级指标的客户数据。数据被复制到每个索引表中。
如果比较的时候,它是通过使用每个键查询的数目的数据是相对静态的这一策略可能是适当的。如果数据是更加动态,保持每个索引表的处理开销可能会变得太大,这种方法是有用的。此外,如果数据量非常大,空间来存储重复的数据所需要的量将显著。
创建由不同的密钥组织的归索引表和通过使用主键而不是重复它引用原始数据,如示于图3中的原始数据被称为一个事实表:
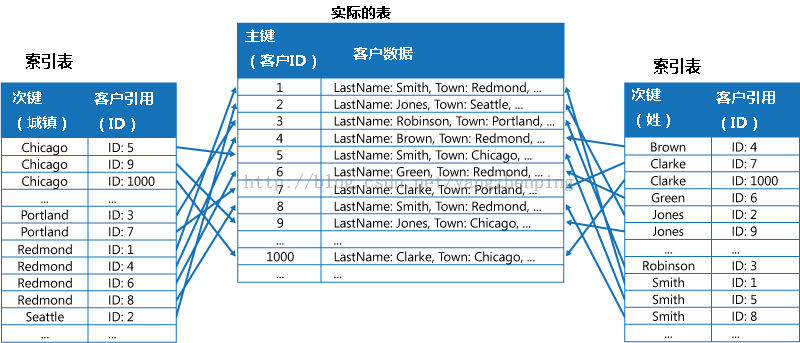
图3 - 索引表执行二级指标的客户数据。该数据是由每个索引表所引用。
这种技术可以节省空间,降低了维护的重复数据的开销。的缺点是,一个应用程序具有通过使用第二密钥来执行两个查找操作以查找数据(找到的主键的索引表中的数据,然后查找在事实表中的数据通过使用主键)。
创建由重复的频繁检索的字段不同的按键组织的部分归索引表。引用原始数据来访问较少频繁访问的字段。图4示出了这种结构。
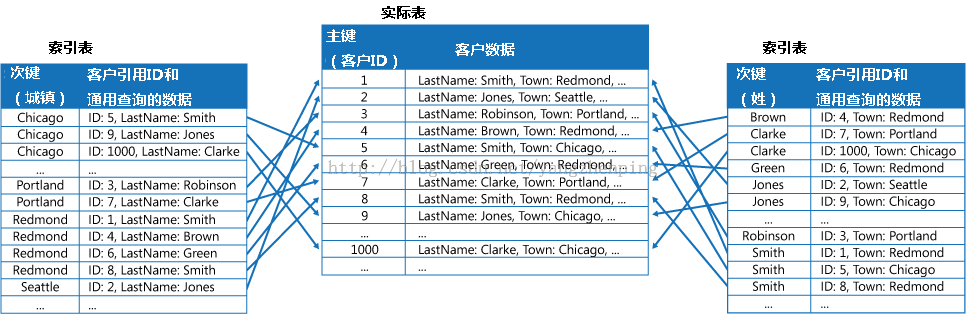
图4 - 索引表执行二级指标的客户数据。经常访问的数据是重复的每个索引表中。
使用这种技术,你可以前两种方法之间取得平衡。可以快速地检索到通过使用单个查找,常用的查询数据,而空间和维护开销是不一样大,复制整个数据集。
如果应用程序通过指定值的组合频繁地查询数据(例如,“查找生活在雷德蒙和具有史密斯的姓所有客户”),则可以实现键的索引表中的项目作为一个级联城市属性和姓氏属性的,如示于图5中的键由镇排序,然后通过名字为那些具有镇相同的值的记录。

图5 - 基于复合主键索引表
索引表可以加快了分片的数据查询操作,并在那里的碎片密钥散列特别有用。图 6 显示了一个示例,其中分片密钥是客户 ID 的散列。索引表可以由非散列值(城市和名字)组织数据,并提供该哈希分片键作为查找数据。这样可以节省从重复计算散列键的应用(其可以是昂贵的操作),如果它需要检索的数据落在一个范围之内,或者它需要读取的数据,以便在非散列密钥。例如,诸如“查找生活在雷德蒙所有客户”可以由通过定位在索引表中的匹配项(其全部存储在一个连续的块),并按照引用的客户数据尽快解决的查询使用存储在索引表中的碎片的键。

图6 - 索引表中提供了快速查找的分片数据
问题和注意事项
在决定如何实现这个模式时,请考虑以下几点:
- 保持辅助索引的开销可能是显著。你必须分析和了解,您的应用程序使用的查询。只创建他们很可能被经常使用的索引表。不要投机创建索引的表,以支持应用程序不执行查询,或者一个应用程序只执行非常偶然。
- 在索引表中复制的数据所用的存储成本和维护数据的多个副本所需的工作条件添加显著开销。
- 执行一个索引表,作为标准化的结构,引用原始数据可能需要的应用程序,以执行两个查找操作以查找数据。第一操作搜索索引表来检索主键,第二个使用的主密钥来获取数据。
- 如果系统包含大量索引表在非常大的数据集,也可以是难以维持索引表和原始数据之间的一致性。有可能设计围绕最终一致性模型的应用。例如,插入,更新或删除数据,一个应用程序可以发送一条消息给一个队列,并让一个独立的任务执行操作和维护引用该数据不同步的索引表。有关实现最终一致性的更多信息,请参阅数据一致性底漆。
注意: 微软 Azure 存储表支持事务更新到同一个分区中保存的数据进行更改(简称实体组的事务)。如果你可以存储一个事实表和在同一个分区的一个或多个索引表中的数据,您可以使用此功能来帮助确保一致性。
索引表可以自行进行分区或分片。
何时使用这个模式
使用这种模式来提高查询性能,当应用程序经常需要使用一键以外的主(或子库)键来检索数据。
这种模式可能不适合时:
- 数据是不稳定的。索引表可能变得过时的速度非常快,使其无效,或者使保持在索引表大于用它制成的任何节省的开销。
- 选作索引表中的二级密钥的场是非常不鉴别,只能有一个小的值的集合(例如,性别)。
- 数据值的选择为一个索引表中的二级密钥的场的平衡是高度倾斜。例如,如果 90% 的记录中包含相同的值中的一个字段,然后创建和维护一个索引表中查找基于该字段中的数据可以施加更大的开销比通过数据扫描顺序。然而,如果查询非常频繁地针对位于对剩余的 10% 的值,该索引可以是有用的。你必须明白的疑问,您的应用程序正在执行,以及如何他们经常执行。
例子
Azure 存储表在云中运行的应用程序提供了一个高度可扩展的键/值数据存储。应用程序存储,并通过指定一个键检索数据值。的数据值可以包含多个字段,但一个数据项的结构是不透明的表存储,这仅仅处理一个数据项作为一个字节数组。
Azure 存储表还支持分片。分片密钥包括两个元件,一个分区键和行密钥。有相同的分区键的数据项都存储在同一分区(碎片),并且项目被存储在一个子库中排键顺序。表存储优化用于执行获取数据下降分区中的连续范围的行键值范围内的查询。如果您正在构建存储在 Azure 的表的信息的云应用,你应该组织你的数据在考虑这个功能。
例如,考虑存储有关电影的信息的应用程序。应用程序经常按流派查询电影(动作片,纪录片,历史,喜剧,戏剧,等等)。可以通过使用类型作为分区键,并指定电影的名称作为行密钥创建一个天青表的分区的每个类型,如图7。
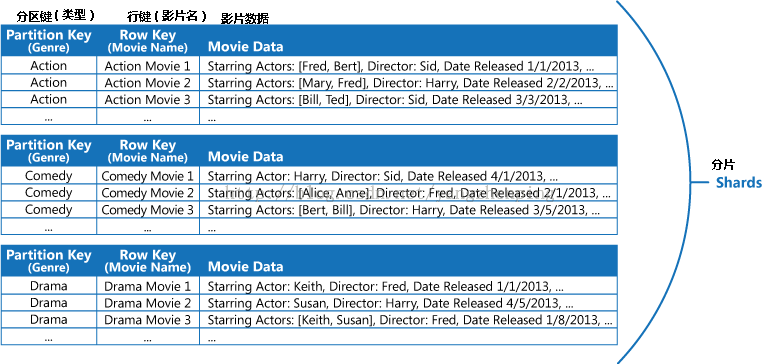
图7 - 存储在 Azure Table 中的电影数据,按流派划分和排序的电影名称
这种方法不太有效,如果该应用程序还需要通过演员主演查询电影。在这种情况下,你可以创建一个单独的Azure表作为一个索引表。分区键是演员和行关键是电影的名字。对于每个演员的数据将被存储在单独的分区。如果一个电影明星不止一个演员,同一部电影会出现在多个分区。
可以通过采用上面的解决方案部分中所述的第一种方式重复在每个分区中保存的值的电影数据。然而,很可能是每个影片将(对于每个演员一次)重复几次,所以它可能是更有效的,以部分非规范化,以支持最常见的查询(如其他演员的姓名)的数据,并实现一个应用程序由包括必要找到在体裁分区的完整信息,分区键来检索任何剩余的细节。这种方法是通过在解决方案部分中的第三项中的说明。图8描述了这种方法。
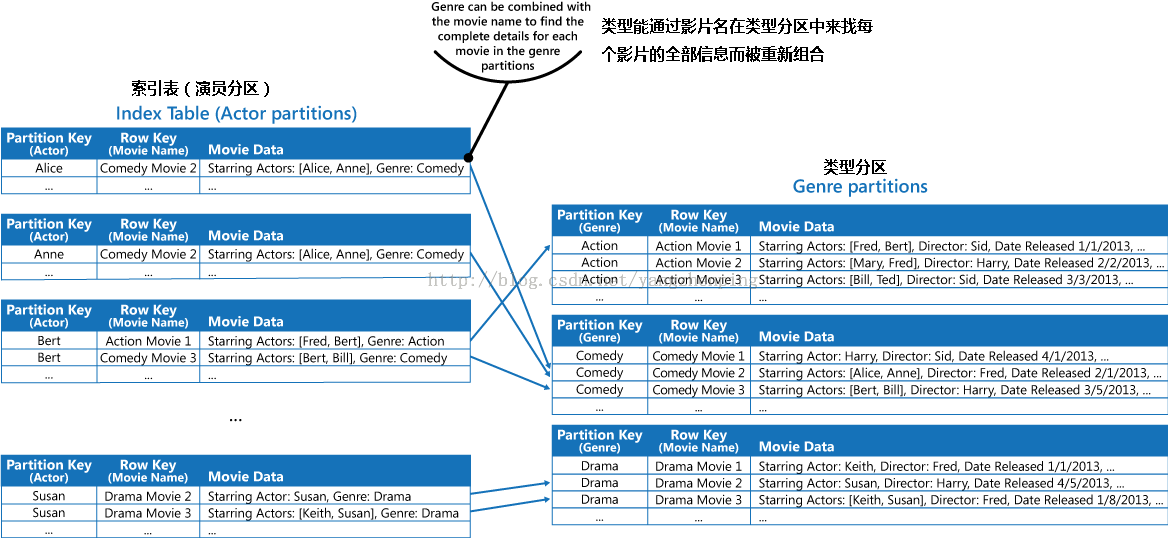
图8 - 演员分区作为索引表的影像数据


更多建议: