
 免费 AI IDE
免费 AI IDE

Assembly 数字协处理器
2018-11-01 11:21 更新
硬件
早期的Intel处理器并没有提供支持浮点操作的硬件。这并不意味着它们不可以执行浮点操作。它仅仅表示它们需要通过由许多非浮点指令组成的程序来执行这些操作。对于早期的系统,Intel提供了一片额外的称为数学协处理器的芯片。相比于使用软件程序,数学协处理器拥有能快速执行许多浮点操作的机器指令(在早期的处理器上,至少快10倍!)。8086/8088的协处理器为8087。80286的协处理器为80287,80386的为80387。80486DX处理器将数学协处理器内置到80486中了。从Pentium开始,所有生产的80x86
处理器都内置数学协处理器;但是,它依然被规划成好像它是一个分离的单元。即使是早期没有协处理器的系统都可以安装一个模拟数学协处理器的软件。当一个程序执行了一条协处理器指令时,这个模拟软件包将自动激活并执行一个软件程序来得到与真实协处理器一样的结果(虽然,毫无疑问,会比较慢)。
处理器都内置数学协处理器;但是,它依然被规划成好像它是一个分离的单元。即使是早期没有协处理器的系统都可以安装一个模拟数学协处理器的软件。当一个程序执行了一条协处理器指令时,这个模拟软件包将自动激活并执行一个软件程序来得到与真实协处理器一样的结果(虽然,毫无疑问,会比较慢)。
数学协处理器有八个浮点数寄存器。每个寄存器储存着80位的数据。在这些寄存器中,浮点数总是储存成80位的扩展精度。这些寄存器称为ST0,ST1,ST2,...ST7。浮点寄存器与主CPU中的整形寄存器的使用方法是不同的。浮点寄存器被当作一个堆栈来管理。回想一下堆栈是一个后进先出(LIFO)队列。ST0总是指向栈顶的值。所有新的数都被加入到栈顶中。已经存在的数被压入到堆栈中,为了为新来的数提供空间。
在数学协处理器中同样有一个状态寄存器。它有几个标志位。只有4个用来比较的标志位将会提到: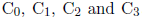 。这些位的使用将在以后讨论。
。这些位的使用将在以后讨论。
。这些位的使用将在以后讨论。指令
为了很容易地将普通的CPU指令和协处理器指令区分开来,所有的协处理器助词符都是以F开头。
导入和储存
用来将数据导入到协处理器寄存器栈顶的指令有几条:

将堆栈中的数据储存到内存的指令同样也有几条。其中有几条指令当它们储存好一个数后,会将这个数从栈中弹出(也就是删除)。

加法和减法
每一条加法指令都是计算ST0和另一个操作数的和。结果总是储存到一个协处理器寄存器中。


减法指令是加法指令的两倍,因为在减法中,操作数的次序是重要的。(也就是说, a+b = b+a,但是,a-b ≠ b-a)。对于每一条指令,都有一条跟它次序相反的反向指令。这些反向指令要都是以R或RP结尾。图6.5展示了一小段代码:对一个双字数组的元素求和。在第10和第13行中,你必须指定内存操作数的大小。否则汇编器将不会知道内存操作数是一个单精度浮点数(双字)还是双精度数(四字)。

乘法和除法
乘法指令和加法指令完全类似。

不要惊讶,除法指令和减法指令非常类似。除以0结果将是一个无穷数。

比较
协处理器同样能执行浮点数的比较操作。FCOM家族的指令就是执行比较操作的。

这些指令会改变协处理器状态寄存器中的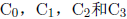 比特位的值。不幸的是,CPU直接访问这些位是不可能的。条件分支指令使用FLAGS寄存器,而不是协处理器中的状态寄存器。但是,使用几条新的指令可以相当容易地将状态字的比特位传递到FLAGS寄存器上相同的比特位中。
比特位的值。不幸的是,CPU直接访问这些位是不可能的。条件分支指令使用FLAGS寄存器,而不是协处理器中的状态寄存器。但是,使用几条新的指令可以相当容易地将状态字的比特位传递到FLAGS寄存器上相同的比特位中。
比特位的值。不幸的是,CPU直接访问这些位是不可能的。条件分支指令使用FLAGS寄存器,而不是协处理器中的状态寄存器。但是,使用几条新的指令可以相当容易地将状态字的比特位传递到FLAGS寄存器上相同的比特位中。
图6.6展示了一小段样例代码。第5行和第6行将 比特位传递到FLAGS寄存器相同的比特位中了。传递了这些比特位,所以它们就类似于两个无符号整形的比较结果。这也是为什么第7行使用JNA指令的缘故。
比特位传递到FLAGS寄存器相同的比特位中了。传递了这些比特位,所以它们就类似于两个无符号整形的比较结果。这也是为什么第7行使用JNA指令的缘故。
比特位传递到FLAGS寄存器相同的比特位中了。传递了这些比特位,所以它们就类似于两个无符号整形的比较结果。这也是为什么第7行使用JNA指令的缘故。

图6.7展示了一个子程序例子:使用FCOMIP指令来找出两个双精度数的较大值。不要把这些指令和整形比较函数(FICOM 和FICOMP)混起来。

以上内容是否对您有帮助:


更多建议: