
 免费 AI IDE
免费 AI IDE

Assembly 类的概念和样例介绍
C++中的类描述了一个对象类型。一个对象包括数据成员(data member)和函数成员(function member)。换句话说就是,它是由跟它相关联的数据和函数组成的一个struct结构体。考虑在图 7.13中定义的那个简单的类。一个Simple类型的变量非常类似于包含一个int成员的标准Cstruct结构体。这些函数并不会储存到指定结构体的内存中。但是,成员函数和其它函数是不一样的。

它们传递了一个隐藏的参数。这个参数是一个指向成员函数能起作用的对象的指针。 例如,考虑图 7.13中的Simple类的成员函数set_data。如果用C语言来 书写此函数,这个函数将像这样:明确传递一个指向成员函数能起作用的 对象的指针,如图 7.14所示。使用DJGPP编译器加上-S选项(gcc和Borland编 译器也是一样)来告诉编译器输出一个包含此代码产生的等价的汇编语 言代码的源文件。对于DJGPP和gcc编译器,此汇编源文件是以.s扩展 名结尾的,但是不幸的是使用的语法是AT&T汇编语言语法,这种语法 和NASM和MASM语法区别非常大。(Borland和MS编译器产生一个以.asm扩展名结尾的源文件,使用的是MASM语法。)

图 7.15展示了将DJGPP的输 出转换成NASM语法后的代码,增加了阐明语句目的的注释。在第一行 中,注意成员函数set_data的函数名被指定为一个改编后的标号,此标号 是通过编码成员函数名,类名和参数后得到的。类名被编码进去的是因为 其它类中可能也有名为set_data的成员函数,而这两个成员函数 必须 使用 不同的标号。参数之所以被编码进去是为了类能通过携带其它参数来重载 成员函数set_data,正如标准的C++函数。但是,和以前一样,不同的编 译器在改编标号时编码信息的方式也不同。
下面的第2和第3行,出现了熟悉的函数的开始部分。在第5行,把堆栈 中的第一个参数储存到EAX中了。这并 不是参数x!替代它的是那个隐藏的参数,它是指向此函数能起作用的对象的指针。第6行将参数x储存 到EDX中了,而第7行又将EDX储存到了EAX指向的双字中。它是Simple对象 中的data成员,也是这个类中的唯一的数据,它储存在Simple结构体中偏 移地址为0的地方。
样例
这一节使用了这章中的思想创建了一个C++类:用来描述任意大小的 无符号整形。因为要描述任意大小的整形,所以它需要储存到一个无符号整形的数组(双字的)中。可以使用动态分配来实现任意大小的整形。双 字是以相反的方向储存的 ( 也就是说 ,双字的最低有效位的下标为0)。 图 7.16展示了Big_int类的定义。Big_int的大小是通过测量unsigned数 组的大小得到的,用来储存它的数据。此类中的size 数据成员的偏移地址 为0,而number_成员的偏移为4。


图 7.16: Big_int类的定义
为了简单化这些例子,只有拥有大小相同的数组的对象实例才可以相互 进行加减操作。 这个类有三个构造函数(constructor):第一个构造函数(第9行)使用了一 个正常的无符号整形来初始化类实例;第二个构造函数(第18行)使用了一个 包含一个十六进制值的字符串来初始化类实例。第三个构造函数(第21行)是拷贝构造函数 (copy constructor)。

因为这里使用的是汇编语言,所以讨论的焦点在于加法和减法运算符如何工作。图 7.17展示了与这些运算符相关的部分头文件。它们展示了如何创建运算符来调用汇编程序。因为不同的编译器使用完全不同的名字改编 规则来改编运算符函数,所以创建了内联的运算符函数来调用C链接汇编程序。这就使得在不同编译器间的移植变得相对容易些,而且和直接调用速 度一样快。这项技术同样免去了从汇编中抛出异常的必要!
为什么在这里使用的全部是汇编语言呢?回想一下,在执行多倍精 度运算时,进位必须从一个双字移去与下一个有效的双字进行加法操作。C++(和C)并不允许程序员访问CPU的进位标志位。只有通过让C++独 立地重新计算出进位标志位后有条件地与下一个双字进行加法操作,才能执行这个加法操作。使用汇编语言来书写代码会更有效,因为它可以访问 进位标志位,可以使用ADC指令来自动将进位标志位加上,这样做更有道 理。
为了简化,只有add_big_ints的汇编程序将在这讨论。下面是这个程序 的代码(来自big_math.asm):
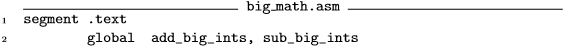



希望,到此刻为止读者能明白大部分这里的代码。第25行到27行将Big_int对 象传递的指针储存到寄存器中。记住引用的仅仅是指针。第31行到35行检查保证三个对象数组的大小是一样的。(注意,size_的偏移被加到指针中了,为了访问数据成员。)第44行和第46行调整寄存器,让它们指向被各自对象使用的数组,用来替代使用对象本身。(同样,number_的偏移被加到 对象指针中了。)
在第52行到57行的循环中,将储存在数组里的整形一起相加,首先加的是最低有效的双字,然后是下一最低有效的双字, 等等。 多倍精度运算必须以这样的顺序来完成(看小节 2.1.5)。第59行用来检查溢出,一旦溢出, 进位标志位将由最后进行加法运算的最高有效位置位。因为数组里的双字 是以little endian顺序储存的,所以循环从数组的开始处开始,依次向前直到结束。
图 7.18展示了Big_int的简单应用的简短的例子。注意,Big_int常量必 须明确声明,如第16行。这有两个原因。首先,没有转换构造函数来将一个无符号整形转换成Big_int类型。其次,只有相同大小的Big _int数才能 用来进行相加操作。这里进行类型转换是有问题的,因为要知道需转换的大小是非常困难的。此类的一个更高级的实现将允许任意大小的数之间的相加。作者不打算因为要实现任意大小的数的相加而把这个例子弄得过度复杂。(但是,鼓励读者来实现它。)



更多建议: