
 免费 AI IDE
免费 AI IDE

JavaScript学习笔记整理(8):DOM
一、DOM
文档对象模型(Document Object Model,DOM)是表示和操作HTML和XML文档内容的基础API。
当网页被加载时,浏览器会根据DOM模型,将结构化文档(比如HTML和XML)解析成一系列的节点,再由这些节点组成一个树状结构(DOM Tree)。
如下图:

上图中的每一个方框是文档的一个节点,它表示一个Node对象,而所有节点组成了节点树(DOM树)。
节点有7中类型:
Document:整个文档树的顶层节点
DocumentType:doctype标签(比如<!DOCTYPE html>)
Element:网页的各种HTML标签(比如<body>、<a>等)
Attribute:网页元素的属性(比如class="right")
Text:标签之间或标签包含的文本
Comment:HTML或XML的注释
DocumentFragment:文档的片段
Document和Element是两个重要的DOM类。
1.1节点之间的关系
在一个节点之上的直接节点是其 父节点 ,在其下一层的直接节点是其 子节点 。在同一层上具有相同父节点的节点是 兄弟节点 。在一个节点之下的所有层级的一组节点是其 后代节点 。一个节点的任何父节点、祖父节点和其上层的所有节点是 祖先节点 。
通用的Document和Element类型与HTMLDocument和HTMLElement类型之间是有严格区别的。
Document类型代表一个HTML或XML文档,Element类型代表该文档中的一个元素。
HTMLDocument和HTMLElement子类只是针对于HTML文档和元素。
CharacterData通常是Text和Comment的祖先,它定义两种节点所共享的方法。
Attr节点类型代表XML或HTML属性。
Element类型定义了将属性当做“名/值”对使用的方法。
DocumentFragment类型在实际文档中并不存在的一种节点,它代表一系列没有常规父节点的节点。
1.2 选取文档元素
在JavaScript中,有多种方法选取元素。
- 用指定的id属性
- 用指定的name属性
- 用指定的标签名字
- 用指定的CSS类
- 匹配指定的CSS选择器
<div id="div"></div>
document.getElementById('div');
1.2.2 用指定名字选取元素
一些HTML元素拥有name属性(比如<form>、<radio>、<img>、<frame>、<embed>和<object>等),非唯一,所以多个元素可能有相同的名字。
基于name属性的值选取HTML元素,可以使用Document对象的getElementsByName()方法,返回一个NodeList对象(类数组对象)。
<input name="input"/>
var inputs = document.getElementsByName('input');
inputs[0].tagName //input
注意:getElementsByName()定义在HTMLDocument类中,而不在Document类中,所以它只针对HTML文档可用,在XML中不可用。
1.2.3 用指定标签名选取元素
Document对象的getElementsByTagName()方法可用来选取指定类型(标签名)的所有HTML或XML元素,也是返回一个NodeList对象
document.getElementsByTagName('span') // 选取所有span元素
给getElementsByTagName()传递通配符参数“*”,将获得一个代表文档中所有元素的NodeList对象。
在Element类中也同样定义了getElementsByTagName()方法,其原理和Document版本是一样的,不过它只选取调用该方法的元素的后代元素。
下面的代码就是查找文档中第一个<p>元素里面的所有<span>元素。
var p = document.getElementsByTagName('p')[0];
var span = p.getElementsByTagName('span');
1.2.4 用指定CSS类选取元素
HTML元素的class属性值是一个以空格隔开的列表,可以为空或包含多个标识符。
在HTML文档和HTML元素上,我们可以调用getElementsByClassName()来选择指定CSS类的元素,它返回一个实时的NodeList对象,包含文档或元素所有匹配的后代节点。
getElementsByClassName()只需要一个字符串参数,但是该字符串可以由多个空格隔开的标识符组成,只有当元素的class属性值包含所有指定的标识符时才匹配。
在Element类中也同样定义了getElementsByClassName()方法,其原理和Document版本是一样的,不过它只选取调用该方法的元素的后代元素。
1.2.5 通过CSS选择器选取元素
Document对象的方法querySelectorAll(),它接受一个CSS选择器的字符串参数,返回一个代表文档中匹配选择器的所有元素的NodeList对象,并不是实时的。如果没有匹配的元素,则返回一个空的NodeList对象。
document.querySelectorAll('.div') //匹配所有class名为div的元素
还有一个querySelector()方法,其原理和querySelectorAll()是一样的,不过它返回第一个匹配的元素(以文档顺序),如果没有匹配的元素就返回null。
它们支持复杂的CSS选择器。
// 选中data-tip属性等于title的元素
document.querySelectorAll('[data-tip="title"]');
// 选中div元素,那些class含ignore的除外
document.querySelectorAll('div:not(.ignore)');
但是,它们不支持CSS伪元素的选择器(比如:first-line和:first-letter)和伪类的选择器(比如:link和:visited),即无法选中伪元素和伪类。
这两个方法在Element节点上也有定义。
1.2.6 document.all[ ]
document.all[ ]也可用来选择元素,不过已经废弃了。
document.all[0] //文档中第一个元素
document.all['navbar'] // id或name为“navbar”的元素
1.3 文档结构和遍历
1.3.3 作为节点树的文档
Document对象、它的Element对象和文档中表示文本的Text对象都是Node对象。
Node属性:
(1)parentNode
该节点的父节点,或者针对类似Document对象应该是null,因为它没有父节点。
(2)childNodes
返回只读的类数组对象(NodeList对象),它是该节点的子节点的实时表。
注意:该属性还包括文本节点和评论节点。
(3)firstChild、lastChild
该节点的子节点中的第一个和最后一个,如果该节点没有子节点则为null
注意:这两个属性返回的除了HTML元素子节点,还可能是文本节点或评论节点。
(4)nextSibling、previousSibling
该节点的兄弟节点中的前一个和下一个。具有相同父节点的两个节点称为兄弟节点。节点的顺序反映了它们在文档中出现的顺序。这两个属性将节点之间以双向链表形式连接起来。
注意:这两个属性返回的除了HTML元素子节点,还可能是文本节点或评论节点。
(5)textContent
返回该节点和它的所有后代节点的文本内容。
<div id="div">我是<span>textContent</span></div>
document.getElementById('div').textContent // 我是textContent
(6)nodeType
该节点的类型。
9:Document节点
1:Element节点
3:Text节点
8:Comment节点
11:DocumentFragment节点
(7)nodeValue
Text节点或者Comment节点的文本内容。只有Text节点和Comment节点的nodeValue可以返回结果,其他类型的节点一律返回null。
(8)nodeName
元素的标签名,以大写形式表示。
nodeType和nodeName
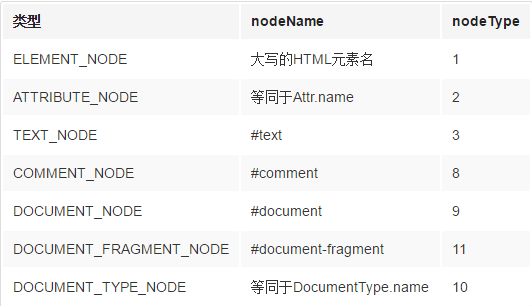
使用这些node属性,我们可以便捷的得到各个节点的引用
document.childNodes[0].childNodes[1]
//等价于
document.firstChild.firstChild.nextSibling
1.3.4 作为元素树的文档
当我们的关注点在文档的元素上而非它们之间的文本上时,JavaScript提供了另外一个API,它将文档看做是E乐门头对象树,忽略部分文档:Text和Comment节点。
属性
(1)children
类似childNodes,返回一个NodeList对象,但children列表只包含Element对象。
注意:Text和Comment节点没有children属性,意味着node.parentNode属性不可能返回Text或Comment节点。任何Element的parentNode总是另一个Element,或者,追溯到树根的Document或DocumentFragment节点。
(2)firstElementChild、lastElementChild
类似firstChild和lastChild,但只代表子Element。
(3)nextElementSibling、previousElementSibling
类似nextSibling和previousSibling,但只代表兄弟Element。
(4)childElementCount
子元素的数量。返回的值和children.length值相等。
(5)offsetParent
offsetParent属性返回当前HTML元素的最靠近的、并且CSS的position属性不等于static的父元素。如果某个元素的所有上层节点都将position属性设为static,则Element.offsetParent属性指向<body>元素。
1.4NodeList对象和HTMLCollection对象
1.4.1 NodeList对象
NodeList实例对象是一个类数组对象,它的成员是节点对象。比如node.childNodes、document.querySelectorAll()返回的都是NodeList实例对象。
document.childNodes instanceof NodeList //true
NodeList实例对象可能是动态集合,也可能是静态集合。所谓动态集合就是一个活的集合,DOM树删除或新增一个相关节点,都会立刻反映在NodeList接口之中。Node.childNodes返回的,就是一个动态集合。
NodeList接口实例对象提供length属性和数字索引,因此可以像数组那样,使用数字索引取出每个节点,但是它本身并不是数组,不能使用pop或push之类数组特有的方法。
1.4.2 HTMLCollection对象
HTMLCollection实例对象与NodeList实例对象类似,也是节点的集合,返回类数组对象。
在HTMLDocument类中,有一些快捷属性来访问各种各样的节点。比如:images、forms和links等属性指向类数组的<img>、<form>和<a>(只包含那些有href属性的<a>标签)元素集合。这些属性都是返回HTMLCollection实例对象。
HTMLDocument也定义了embeds和plugins属性,它们是同义词,都是HTMLCollection类型的<embed>元素的集合。anchors是非标准属性,它指代有一个name属性的<a>元素。
在HTML5中,加入了scripts,它是HTMLCollection类型的<script>元素的集合。
HTMLDocument对象还定义了两个属性,它们指代特殊的单个元素而非元素的集合。
document.body是一个HTML文档的<body>元素,document.head是<head>元素。
如果文档源代码未显式的包含<head>和<body>元素,浏览器将隐式的创建它们。
Document类的documentElement属性指代文档的根元素,在HTML文档中,它总是指代<html>元素。
HTMLCollection与NodeList的区别:
- HTMLCollection实例对象的成员只能是Element节点,NodeList实例对象的成员可以包含其他节点。
- HTMLCollection实例对象都是动态集合,节点的变化会实时反映在集合中。NodeList实例对象可以是静态集合。
- HTMLCollection实例对象可以用id属性或name属性引用节点元素,NodeList只能使用数字索引引用。
HTMLCollection实例的item方法,可以根据成员的位置参数(从0开始),返回该成员。如果取不到成员或数字索引不合法,则返回null。
HTMLCollection实例的namedItem方法根据成员的ID属性或name属性,返回该成员。如果没有对应的成员,则返回null。这个方法是NodeList实例不具有的。
1.5 元素的内容
1.5.1 作为HTML的元素内容
(1)innerHTML
读取Element的 innerHTML 属性作为字符串标记返回那个元素的内容。
<div id="div"><p>123</p></div>
var d = document.getElementById('div');
d.innerHTML // "<p>123</p>"
除了获取,还可以设置
d.innerHTML = '<span>99</span>'
// <div id="div"><span>99</span></div>
(2)outerHTML
outerHTML属性返回一个字符串,内容为指定元素节点的所有HTML代码,包括它自身和包含的所有子元素。
d.outerHTML
// "<div id="div"><p>123</p></div>"
outerHTML属性是可读写的,当设置元素的outerHTML时,元素本身被新的内容所替换。
注意:只有Element节点有outerHTML属性,Document节点没有。
(3)insertAdjacentHTML()
将任意的HTML标记字符插入到指定的元素“相邻”的位置。
传入两个参数:标记是该方法的第二个参数,并且“相邻”的精确含义依赖于第一个参数的值;第一个参数有以下值之一的字符串:“beforebegin”、“afterbegin”、“beforeend”和“afterend”。如下图:

1.5.2 作为纯文本的元素内容
当要查询纯文本形式的元素内容或在文档中插入纯文本(不必转义HTML标记中使用的尖括号后台&符号)时,我们使用node的textContent属性来实现:
<div id="div"><p>123</p></div>
var d = document.getElementById('div');
d.textContent //123
textContent属性就是将指定元素的所有后代Text节点简单的串联在一起。
textContent是可读写的:
d.textContext = '<span>45</span>';
//<span>45</span>
上面代码在插入文本时,会将<span>标签解释为文本,而不会当作标签处理。
注意:在IE中,使用innerText替代textContent。
1.6 创建、插入和删除节点
1.6.1 创建节点
(1)createElement()
创建新的Element节点可以使用Document对象的createElement()方法。给方法传递一个元素的标签名作为参数(对HTML文档来说该标签名是不区分大小写的)
var span = document.createElement('span')
(2)createTextNode()
创建一个Text节点,参数为所要生成的文本节点的内容。
var newnode = document.createTextNode('content')
(3)createAttribute()
生成一个新的属性对象节点,并返回它。参数是属性的名称。
(4)cloneNode()
用来复制已存在的节点。每个节点有一个cloneNode()方法,返回该节点的一个全新副本。传递一个可选的布尔值为参数,如果参数true则同时克隆该节点的所有后代节点,否则只克隆该节点,默认为false。
1.6.2 插入节点
我们可以用node的方法appendChild()或insertBefore()来讲新节点插入到文档中。
(1)appendChild()
接受一个节点对象作为参数,将其作为最后一个子节点,插入当前节点。
parentNode.appendChild(newNode)
(2)insertBefore()
用于将某个节点插入当前节点的指定位置。它接受两个参数,第一个参数是所要插入的节点,第二个参数是当前节点的一个子节点,新的节点将插在这个节点的前面。该方法返回被插入的新节点。
parenNode.insertBefore(newNode,oldNode)
注意:调用上面两个方法时,如果要插入的节点是已存在文档中的,那个节点将自动从它当前的位置移除并在新的位置重新插入。
Node对象并不存在insertAfter方法,如果你要将新节点插入到该节点的后面时,可以这样写:
function insertAfter(parentNode,newNode,oldNode){
if(oldNode.nextSibling){
parentNode.insertBefore(newNode,oldNode.nextSibling);
}else{
parentNode.appendChild(newNode);
}
}
1.6.3 删除和替换节点
(1)removeChild()
从文档树中删除一个节点。
注意:该方法不是在待删除的节点上调用,而是在其父节点上调用。在父节点上调用该方法,并将需要删除的子节点作为方法参数传递给它。
n.parentNode.removeChild(n);
(2)replaceChild()
删除一个子节点并用一个新节点替换它。也是在父节点上调用该方法,第一个参数是新节点,第二个参数是需要替代的节点。
var span = document.createElement('span');
n.parentNode.replaceChild(span,n);
1.6.4 DocumentFragment
DocumentFragment是一种特殊的Node,它作为其他节点的一个临时的容器。
var frag = docment.createDocumentFragment();
DocumentFragment是独立的,而不是任何其他文档的一部分。它的parentNode总是为null。但类似Element,它可以有任意多的子节点,也可以使用appendChild()等方法。
DocumentFragment的特殊之处在于它使得一组节点被当做一个节点看待。
1.7盒状模型
1.7.1 文档坐标和视口坐标
元素的位置是以像素来度量的,向右代表X坐标的增加,向下代表Y坐标的增加。
坐标系的原点:元素的X和Y坐标可以相对于文档的左上角或者相对于其显示文档的视口的左上角。
视口:实际显示文档内容的浏览器的一部分,不包括浏览器“外壳”(如菜单、工具条和标签页)。
文档:是基于整个网页。
1.7.2 查询元素的几何尺寸
我们可以调用getBoundingClientRect()方法来判定一个元素的尺寸和位置。它不需要参数,返回一个有width、height、left、right、top和bottom属性的对象。
getBoundingClientRect()方法返回元素在视口坐标中的位置。
getBoundingClientRect方法返回的rect对象,具有以下属性(全部为只读)。
x:元素左上角相对于视口的横坐标
left:元素左上角相对于视口的横坐标,与x属性相等
right:元素右边界相对于视口的横坐标(等于x加上width)
width:元素宽度(等于right减去left)
y:元素顶部相对于视口的纵坐标
top:元素顶部相对于视口的纵坐标,与y属性相等
bottom:元素底部相对于视口的纵坐标
height:元素高度(等于y加上height)
由于元素相对于视口(viewport)的位置,会随着页面滚动变化,因此表示位置的四个属性值,都不是固定不变的。如果想得到绝对位置,可以将left属性加上window.scrollX,top属性加上window.scrollY。
注意:getBoundingClientRect方法的所有属性,都把边框(border属性)算作元素的一部分。也就是说,都是从边框外缘的各个点来计算。因此,width和height包括了元素本身 + padding + border。
1.7.2 判断元素在某点
elementFromPoint()方法,传递X和Y坐标(使用视口坐标),该方法返回在指定位置的一个元素。
1.7.3 滚动
Element.scrollLeft属性表示网页元素的水平滚动条向右侧滚动的像素数量,Element.scrollTop属性表示网页元素的垂直滚动条向下滚动的像素数量。对于那些没有滚动条的网页元素,这两个属性总是等于0。
如果要查看整张网页的水平的和垂直的滚动距离,要从document.body元素上读取。
document.body.scrollLeft
document.body.scrollTop
这两个属性都可读写,设置该属性的值,会导致浏览器将指定元素自动滚动到相应的位置。
scrollTop()
也可以调用window对象的scrollTop()方法来滚动,接受一个点的X和Y坐标(文档坐标),并作为滚动条的偏移量设置它们。
scrollBy()
用于将网页移动指定距离,单位为像素。它接受两个参数:向右滚动的像素,向下滚动的像素。
scrollIntoView()
该方法保证了元素在视口中可见。在默认情况下,它试图将元素的上边缘放在或尽量接近视口的上边缘。如果只传递false作为参数,它将试图将元素的下边缘放在或尽量靠近视口的下边缘。默认true。
类似锚点滚动。
1.7.4 属性
所有文档元素都有下面的属性:
(1)clientWidth、clientHeight
clientHeight 属性返回元素节点可见部分的高度, clientWidth 属性返回元素节点可见部分的宽度。
所谓“可见部分”,指的是不包括溢出(overflow)的大小,只返回该元素在容器中占据的大小,对于有滚动条的元素来说,它们等于滚动条围起来的区域大小。
这两个属性的值不包括滚动条、边框和Margin,只包含内容和它的内边距,单位为像素。
对于整张网页来说,当前可见高度(即视口高度)要从document.documentElement对象上获取,等同于window.innerHeight属性减去水平滚动条的高度。
没有滚动条时,这两个值是相等的;有滚动条时,前者小于后者。
var rootElement = document.documentElement; // 没有水平滚动条时
rootElement.clientHeight === window.innerHeight // true // 没有垂直滚动条时
rootElement.clientWidth === window.innerWidth // true
对于<i>、<code>和<span>这些内联元素,clientWidth和clientHeight总是0
(2)clientLeft、clientTop
clientLeft 属性等于元素节点左边框(left border)的宽度, clientTop 属性等于网页元素顶部边框的宽度,单位为像素。
但是如果元素有滚动条,并且浏览器将这些滚动条放置在左侧或顶部(极少见),这两个属性就包括了滚动条的宽度,但不包括Margin和Padding。
如果元素是内联元素,clientLeft和clientTop属性总是为0。
(3)scrollWidth、scrollHeight
scrollHeight 属性返回某个网页元素的总高度, scrollWidth 属性返回总宽度,也就是元素的内容加上它的内边距再加上任何溢出内容的尺寸。这两个属性是只读属性。
它们返回的是整个元素的高度或宽度,包括由于存在滚动条而不可见的部分。默认情况下,它们包括Padding,但不包括Border和Margin。
(4)scrollLeft、scrollTop
scrollLeft 属性表示网页元素的水平滚动条向右侧滚动的像素数量, scrollTop 属性表示网页元素的垂直滚动条向下滚动的像素数量。对于那些没有滚动条的网页元素,这两个属性总是等于0。
如果要查看整张网页的水平的和垂直的滚动距离,要从document.body元素上读取。
document.body.scrollLeft
document.body.scrollTop
这两个属性都可读写,设置该属性的值,会导致浏览器将指定元素自动滚动到相应的位置。
(5)offsetWidth、offsetHeight
offsetHeight 属性返回元素的垂直高度, offsetWidth 属性返回水平宽度。这两个属性值包括Padding和Border、以及滚动条,也就是说从边框的左上角开始计算,这也意味着,offsetHeight只比clientHeight少了边框的高度。它们的单位为像素,都是只读。
整张网页的高度,可以在document.documentElement和document.body上读取。
// 网页总高度
document.documentElement.offsetHeight
document.body.offsetHeight
// 网页总宽度
document.documentElement.offsetWidth
document.body.offsetWidth
(6)offsetLeft、offsetTop
offsetLeft 返回当前元素左上角相对于 offsetParent节点的垂直偏移, offsetTop 返回水平位移,单位为像素。通常,这两个值是指相对于父节点的位移。
1.8 其他文档特性
1.8.1 Document
Document属性
(1)document.cookie
用来操作浏览器Cookie
(2)domain
返回当前文档的域名
(3)lastModified
包含文档修改时间的字符串
(4)location
与window对象的location属性引用同一个location对象
(5)referrer
document.referrer属性返回一个字符串,表示当前文档的访问来源,如果是无法获取来源或是用户直接键入网址,而不是从其他网页点击,则返回一个空字符串。
(6)title
文档的<title>和</title>标签之间的内容,可读写。
(7)URL
文档的URL。只读字符串而不是location对象。该属性值与location.href的初始值相同。
(8)doctype
document对象一般有两个子节点。第一个子节点是document.doctype,它是一个对象,包含了当前文档类型(Document Type Declaration,简写DTD)信息。对于HTML5文档,该节点就代表<!DOCTYPE html>。如果网页没有声明DTD,该属性返回null。
(9)documentElement
document.documentElement属性返回当前文档的根节点(root)。它通常是document节点的第二个子节点,紧跟在document.doctype节点后面。
(10)defaultView
document.defaultView属性,在浏览器中返回document对象所在的window对象,否则返回null。
document.defaultView === window // true
(11)activeElement
document.activeElement属性返回当前文档中获得焦点的那个元素。用户通常可以使用Tab键移动焦点,使用空格键激活焦点。比如,如果焦点在一个链接上,此时按一下空格键,就会跳转到该链接。
(12)characterSet
document.characterSet属性返回渲染当前文档的字符集,比如UTF-8、ISO-8859-1。
(13)readyState
document.readyState属性返回当前文档的状态,共有三种可能的值。
loading:加载HTML代码阶段(尚未完成解析)
interactive:加载外部资源阶段时
complete:加载完成时
(14)compatMode
compatMode属性返回浏览器处理文档的模式,可能的值为BackCompat(向后兼容模式)和CSS1Compat(严格模式)。
一般来说,如果网页代码的第一行设置了明确的DOCTYPE(比如<!doctype html>),document.compatMode的值都为CSS1Compat。
Document方法
(1)document.write()、document.writeIn()
document.write()方法会将其字符串参数连接起来,然后将结果字符串插入到文档中调用它的脚本元素的位置。当脚本执行结束,浏览器解析生成的输出并显示它。
document.writeIn(),类似document.write(),只是在其参数的输出之后追加一个换行符。
1.8.2 查询选取的文本
标准的window.getSelection()方法返回一个Selection对象,后者描述了当前选取的一系列一个或多个Range对象。
1.8.3 可编辑的内容
我们可以设置任何标签的HTML contenteditable属性或者用JavaScript设置对应元素的contenteditable属性,使得元素的内容变成可编辑。
<div contenteditable="true"></div>
当你让标签的内容变成可编辑时,有些浏览器会默认开启检查,如果你不需要时,可以这样设置:
<div contenteditable="true" spellcheck="false"></div>
在当今的一些富文本编辑中,常常使用iframe来当文本框,只需将Document对象的designMode属性设置为字符串“on”就可使得整个文档可编辑(“off”将恢复只读文档)。
<iframe id="editor"></iframe>
var editor = document.getElementById('editor');
editor.contentDocument.designMode = 'on';
由于designMode属性并没有对应的HTML属性,所以要使用contentDocument属性。
1.8.4 execCommand()方法
Document对象的execCommand()方法可以让我们很方便的插入元素或者改变样式。
document.execCommand(aCommandName, aShowDefaultUI, aValueArgument)
参数
- aCommandName:一个 DOMString ,命令的名称。
- aShowDefaultUI:一个 Boolean 是否展示用户界面,一般为 false。Mozilla 没有实现。
- aValueArgument:一些命令需要一些额外的参数值(如insertimage需要提供这个image的url)。默认为null。
document.queryCommandSupport()
传递命令来查询浏览器是否支持该命令
document.queryCommandEnabled()
查询当前使用的命令
document.queryCommandState()
判断命令当前的状态。
document.queryCommandValue()
查询该值。
document.queryCommandIndeterm()


更多建议: