


软件工程 设计的复杂性
复杂性代表事件或事物的状态,它们具有多个相互关联的链接和高度复杂的结构。在软件编程中,随着软件设计的实现,元素的数量以及它们之间的相互联系逐渐变得庞大,一下子变得难以理解。
如果不使用复杂性指标和度量,软件设计复杂性很难评估。让我们看看三个重要的软件复杂性度量。
Halstead's 的复杂性度量
1977年,Maurice Howard Halstead 先生引入了度量软件复杂性的指标。Halstead 的度量取决于程序的实际实现及其度量,这些度量是直接从源代码的运算符和操作数以静态方式计算的。它允许评估 C/C++/Java 源代码的测试时间、词汇、大小、难度、错误和工作量。
根据 Halstead 的说法,“计算机程序是一种算法的实现,该算法被认为是可以归类为运算符或操作数的令牌集合”。Halstead 度量将程序视为运算符及其相关操作数的序列。
他定义了各种指标来检查模块的复杂性。
| 参数 | 意义 |
|---|---|
| n1 | 独特的营办商数目 |
| n2 | N独特的操作数数 |
| N1 | 运营商的总发生数 |
| N2 | 操作数的总发生数 |
当我们在指标查看器中选择源文件以查看其复杂性细节,以下结果是指标报告:
| 指标 | 意义 | 数学表示 |
|---|---|---|
| n | 词汇表 | n1 + n2 |
| N | 大小 | N1 + N2 |
| V | 成交量 | 长* LOG2词汇 |
| D | 难度 | (n1/2) * (N1/n2) |
| E | 努力 | 难度*体积 |
| B | 错误 | 成交量 / 3000 |
| T | 测试时间 | 时间=努力/ S,S = 18秒. |
圈复杂度度量
每个程序包含要执行的语句,以执行某些任务和其他决定需要执行哪些语句的决策语句。这些决策结构改变了程序的流程。
如果比较两个相同大小的程序,由于程序的控制跳转频繁,决策语句较多的程序会更加复杂。
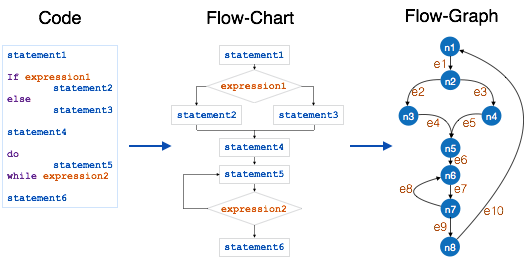
McCabe 在 1976 年提出了圈复杂度度量来量化给定软件的复杂度。它是基于程序决策结构的图驱动模型,例如 if-else、do-while、repeat-util、switch-case 和 goto 语句。
制作流程控制图的过程:
- 将程序分成较小的块,由决策结构分割。
- 创建代表每个节点的节点。
- 连接节点,如下所示:
- 如果可以控制从块 i 分支到块 J
画一条弧 - 从出口节点到入口节点
画一条弧.
- 如果可以控制从块 i 分支到块 J
为了计算程序模块的圈复杂度,我们使用公式:
V(G) = e – n + 2
Where
e is total number of edges
n is total number of nodes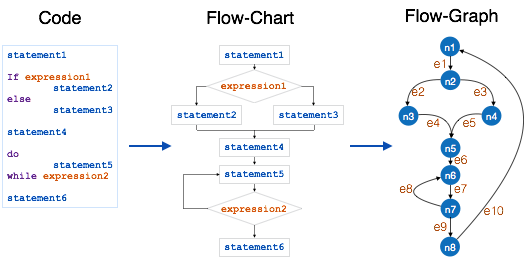
上述模块的圈复杂度为:
e = 10
n = 8
Cyclomatic Complexity = 10 - 8 + 2
= 4根据 P. Jorgensen, 一个模块的圈复杂度不应超过10.
功能点
它被广泛用于衡量软件的大小。功能点专注于系统提供的功能。系统的特性和功能用于衡量软件的复杂性。
功能点依赖于五个参数,分别命名为外部输入、外部输出、逻辑内部等我呢间、外部接口文件和外部查询。为了考虑软件的复杂性,每个参数都被进一步分类为简单、平均或复杂。
让我们来看看功能点的参数:
外部输入
来自外部的系统的每个独特输入都被视为外部输入。测量输入的唯一性,因为没有两个输入应该具有相同的格式。这些输入可以是数据或控制参数。
- 简单 - 如果输入计数较低并且影响较少的内部文件
- 复杂 - 如果输入计数较高并且影响较多的内部文件
- 平均 - 介于简单和复杂之间
外部输出
系统提供的所有输出类型窦计入此类别。如果输出格式和处理是唯一的,则输出被认为是唯一的。
- 简单 - 如果输出计数低
- 复杂 - 如果输出计数高
- 平均 - 介于简单和复杂之间
逻辑内部文件
每个软件系统都维护内部文件,以维护其功能信息并正常运行。这些文件保存系统的逻辑数据。该逻辑数据可能包含功能数据和控制数据。
- 简单 - 如果记录类型的数量很少
- 复杂 - 如果记录类型的数量很多
- 平均 - 介于简单和复杂之间
外部接口文件
软件系统可能需要与某些外部软件共享其文件,或者可能需要将文件传递给处理或作为参数传递给某些函数。所有这些文件都算作外部接口文件。
- 简单 - 如果共享文件的记录类型数量很低
- 复杂 - 如果共享文件的记录类型数量很高
- 平均 - 介于简单和复杂之间
外部查询
查询是输入和输出的结合,用户发送一些要查询的数据作为输入,系统将查询的输出处理后响应用户。查询的复杂性不仅仅是外部输入和外部输出。如果查询的输入和输出在格式和数据方面是唯一的,则称该查询是唯一的。
- 简单 - 如果查询需要低处理并昌盛少量输出数据
- 复杂 - 如果查询需要高处理并产生大量输出数据
- 平均 - 介于简单和复杂之间
系统中的这些参数中的每一个都根据它们的类别和复杂性被赋予权重。下表列出了每个参数的权重:
| 参数 | 简单 | 平均 | 复杂 |
|---|---|---|---|
| 输入 | 3 | 4 | 6 |
| 输出 | 4 | 5 | 7 |
| 查询 | 3 | 4 | 6 |
| 文件 | 7 | 10 | 15 |
| 接口 | 5 | 7 | 10 |
上表产生原始功能点。这些功能点根据环境复杂度进行调整,系统使用十四种不同的特征来描述:
- 数据通信
- 分布式处理
- 绩效目标
- 操作配置负载
- 成交率
- 在线数据录入
- 终端用户效率
- 在线更新
- 复杂处理逻辑
- 可重用性
- 安装方便
- 操作简便
- 多个网站
- 渴望促进变化
然后将这些特征因素评级为 0 到 5,如下所述:
- 无影响
- 非主要的
- 缓和的
- 平均数
- 重要的
- 必要的
然后将所有评级相加为 N。N 的值范围从 0 到 70(14钟特性 x 5 种评级)。它用于计算复杂性调整因子(CAF),使用以下公式:
CAF = 0.65 + 0.01N然后,
交付功能点 (FP)= CAF x Raw FP然后可以将此 FP 用于各种指标,例如:
- 成本 Cost = $ / FP
- 质量 Quality = Errors / FP
- 生产力 Productivity = FP / person-month


更多建议: