


海量数据存储基础
原文出处:http://weibo.com/p/1001643874615465508614
作者:毕建坤@bijiankun

微博平台研发作为微博的底层数据及业务支撑部门,已经经历了5年的发展历程。伴随着从数据及业务暴发式增长,我们在海量数据存储方面遭遇了诸多挑战,与此同时也伴随着丰富经验的积累。
本次新兵训练营,受众在于应届毕业生,目的在于让新同学系统化并且有针对性的了解平台的核心技术及核心业务,以使新同学在新兵训练营结束后,能够对平台的底层架构与业务有一定的了解。
本文主要面向新同学介绍平台的核心技术之一——海量数据存储,主要介绍在海量数据存储在大规模分布式系统下的架构变迁与设计。
课程大纲:
一、课程目标
1. 了解存储服务概况,以及RDBMS及NoSQL的差异
2. 理解MySQL、Redis、HBase基本实现机制、特性、适用场景
3. 理解几种存储产品的大规模分布式服务方案
4. 学会使用平台的MySQL、Redis client组件
5. 理解对于MySQL、Redis分布式系统设计想要注意的问题
6. 了解平台几种典型案例
7. 理解几种存储产品在平台的定制修改与名词术语
二、存储服务概述
1. 关系型数据库是基于实体关系模型(Entity-Relationship Model)的数据服务,具备以下特点。
-
适合存储结构化数据
-
查询语言SQL,insert delete update select
-
主流关系型数据库多是持久化存储系统,系统性能与机器性能相关性较大
-
几类主流的 关系型数据库
-
-
MySQL
-
Oracle
-
DB2
- SQL Server
-
-
性能
-
-
局限于服务器性能,与其是磁盘性能
-
局限于数据复杂度
- 常见的SSD磁盘服务器,单机读取性能可达万级/s
-
大型互联网服务大多采用MySQL进行作为关系型数据库,微博平台的核心业务(如微博内容用户微博列表)也同样如此
本次培训也会着重介绍MySQL及其分布式架构方案。
2. NoSQL(Not only SQL)数据库,泛指非关系型的数据库,兴起的契机在于传统关系型数据库应对大规模、高并发的能力有限,而NoSQL的普遍性能优势能够弥补关系型数据库在这方面的不足
-
存储非结构化数据、半结构化数据
- 性能
业界使用的NoSQL多为内存集中型服务,受限于I/O及网络,通常请求响应时间在毫秒级别,单机QPS在10万级别(与数据大小及存储复杂度相关)
-
常见的几类NoSQL产品
-
K-V(Memcached、Redis),这类NoSQL产品在互联网业内应用范围最广。Memcached提供具备LRU淘汰策略的K-V内存存储;而Redis提供支持复杂结构(List、Hash等)的内存及持久化存储
-
Column(HBase、Cassandra),HBase是基于列式存储的分布式数据库集群系统
-
Document(MongoDb)
- Graph(Neo4J),最庞大、最复杂的Graph模型是人的关系,理论上用图描述并且用Graph数据库存储最合适不过,不过目前的数据规模、系统性能仍然有待优化
web2.0时代,NoSQL产品在互联网行业中的重要性随着互联网及移动互联网的发展而与日剧增 大型互联网应用,为应对大规模、高并发访问,大多都引入了NoSQL产品,其中Memcached、Redis以其高成熟度、高性能、高稳定性而被广泛使用。微博平台也具备千台规模的NoSQL集群,微博核心的Feed业务、关系业务也都依赖Memcached及Redis提供高性能服务
本次培训,会着重介绍Redis及其分布式架构
三、MySQL与MySQL分布式架构设计
微博平台核心业务的数据都存储在MySQL上,目前具备千台规模的集群,单个核心业务数据突破千亿级,单个核心业务QPS峰值可达10万级每秒,写入也是万级每秒。
在海量数据并且数据量持续增长的景下,在如何设计满足 高并发(w/r)、低延时(10ms级别)、高可用性(99.99%)的分布式MySQL系统方面,我们已经具备充足的经验并且依然在持续攻坚这一问题,而我们的课程也会着重介绍海量数据存储之MySQL。
1. MySQL简介
-
MySQL是一个关系型数据库系统RDBMS
-
使用SQL作为查询语言
-
开源
-
存储引擎
-
Innodb 支持事务、行锁,写入性能稍差
-
MyIsam 不支持事务,读写性能略好
-
满足ACID特性
-
主键、唯一键、外键(大规模系统一般不用)
-
Transaction,事务即一系列操作,要么完全地执行,要么完全地不执行
-
服务、端口、实例,都是指 服务端启动的一个MySQL数据库
-
性能
-
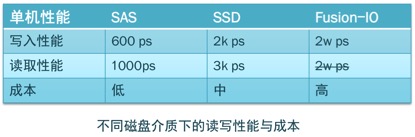
-
随着磁盘性能升高,读写性能也逐步升高,但成本也随之增加
-
数据库的写入性能:写入tps随着并发量增加而增加,但上升到一定瓶颈,增速放缓至并发数临界点后 tps会急剧下滑
-
思考:如果对性能有更高(超出上述三种存储介质并发量级)的要求怎么办?
-
定制存储:针对服务特点,定制存储,定制更适合自己业务场景的存储产品。然而一般业界成熟产品为考虑通用性而会牺牲部分性能
- 引入NoSQL
-
2. 从单机到集群的架构变迁
-
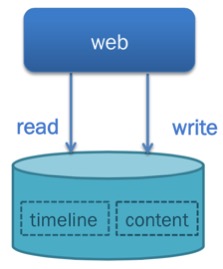
业务上线初期,web服务规模较小,一般具备以下特点
-
-
服务原型时期,用户基数小,多种业务公用资源,日均写入百万级别,读取千万级别
-
数据规模小,单机性能能够满足需求
-
用户规模小,开发重心偏向迭代速度
考虑到上述小型业务特点,为节约资源成本及开发成本,可以采用多个业务混合部署形式
-
-
当用户增多,数据量、访问量升高(2倍以下),数据库压力较大,怎样在有限程度提高MySQL吞吐量呢?
-
-
SQL优化
- 硬件升级
压力还在有限的范围内增长,通过简单、低成本优化,可以一定成都上提高有限的服务性能
-
-
业务持续发展,读取性能出现瓶颈&&各业务互相影响,多个业务出 现资源抢占,如何快速解决业务抢占问题以提高服务性能?
-
-
垂直拆分——按业务进行数据拆分
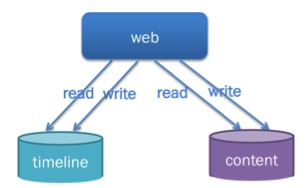
按业务进行拆分,以使业务隔离,timeline的压力增加,不会影响content数据库服务性能;进行拆分后,资源增加,服务性能也相应提升。
-
-
随着业务的继续发展,读取性能出现瓶颈,读写互相影响,如何确保读请求量的增加,不要影响写入性能?相反写入请求量增加如何确保不影响读取性能?(写入性能出现问题会造成数据丢失)
-
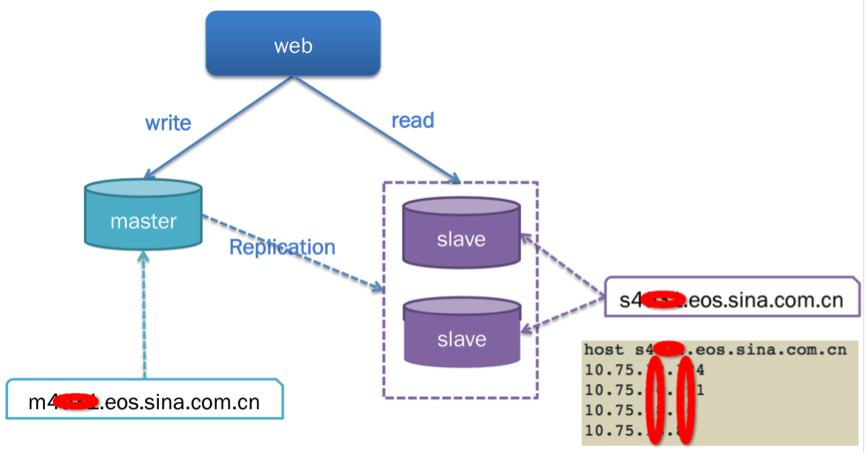
读写分离,写入仅写master,master与slave自动同步;读取仅以slave作为来源
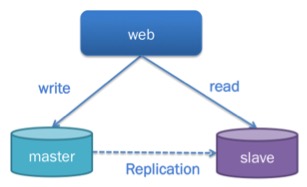
读写分离后,slave仅专注于承担读请求,读取性能得到优化;同里独立的master服务的写入性能也得到优化。
-
一台/一对M-S服务器性能终归是很有限的,当单实例服务性能无法承载线上的请求量时,如何进行优化?
-
-
升级为一主多从架构
-
一个master承载所有写入请求,理论上master性能不变
-
多个slave分担读取请求,读取性能提升n倍
-
-
随着业务量的增长,服务出现如下变化:
-
数据量增长,意味着原本的存储空间不足
-
写入量增长,意味着master写入性能存在瓶颈
- 读取量增长,意味着slave读取性能也存在瓶颈,但通过扩充slave是有限制的:一方面M-S replication性能有风险;另一方面扩充slave的成本较高
如何优化以解决上述问题?
-
水平拆分
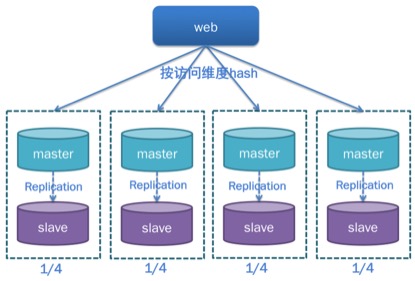
业务经历数据量的增长、读写请求量的增长,数据库服务已经演进为分布式架构,一个业务的数据,怎样合理的分布到上述复杂的分布式数据库是下一个需要解决的问题
3. 如何基于上述演进到最后的架构进行数据库设计呢?
-
分布式数据库设计
-
hash拆分方式,既按hash规则,将数据读写请求分散到多个实例上,见上述水平拆分示意图
-
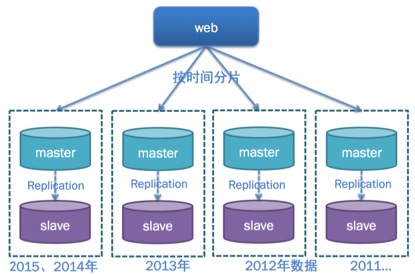
时间拆分方式,基于确定好的时间划分规则,将数据按时间段分散存储再多个实例中
数据分布到一个分布式数据库内,一个实例存储1/n的数据,一个实例只需要一个数据库就能够满足功能需求。
经历几年的发展,数据规模会成倍增长,当需要再次水平扩容(4太→8台),需要通过程序,将数据一分为二,数据迁移成本较高,需要开发人员介入。
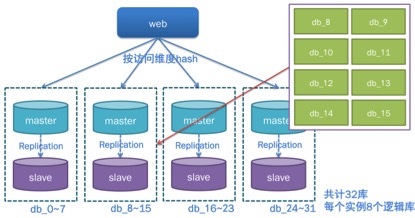
如果在数据库设计时,一个就预先建好2个数据库 ,每个数据库存储1/n/2的数据,需要水平扩容时,即可完整迁移一个数据库,而无需开发人员干预。
在一个数据库实例上,建立的多个数据库,称为逻辑库。
-
逻辑库设计
-
-
逻辑库是相对与物理库而言的概念:物理库只数据库服务的实例;逻辑库指在一个数据库实例上创建的多个database
-
定义逻辑库的目的是便于扩容。假如4台数据库服务器,每台上的物理库包含8个逻辑库,当系统出现容量、写入量瓶颈时,可以新增一倍即4台服务器,直接以同步方式同步数据库,而不需要单独编写应用程序利用进行导入
-
4. 基于上述分布式数据库下的表拆分设计方式
-
hash拆分方式:按hash规则将一个数据库的数据,分散hash到多张表中
-

-
适合数据规模有限的数据集
- 适合增长速度可控的数据集
结合数据库的hash模型如图:
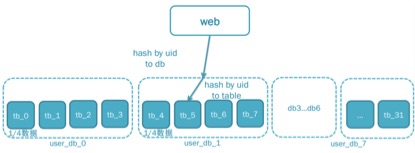
- 根据uid hash到uid所在到数据库,然后再hash到数据库_1下的tb_5表
-
-
按时间拆分方式,按时间规则将同一时段的数据存储在一张表,多个时段时间存储在多张表。例如按月划分,每个月表存储一个月的数据,如果需要获取全部数据需要跨越多个月表
-

-
适合存储增速较快的数据集
- 但查询数据需要跨越多个时间段的表
结合数据库的hash模型如图:
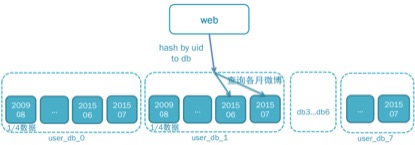
- 根据uid hash到所在的数据库db_1,然后再查找201507 201506获取两个月的数据
思考一个问题:如何能够快速定位,一个人的第1000条到1100条数据呢?
-
-
二级索引快速定位(一级)索引位置
-
-
描述数据在以及索引中的分布状况
-
用于快速定位/缩小查询范围
-
一般情况字段列表:uid, date_time, min_id, count
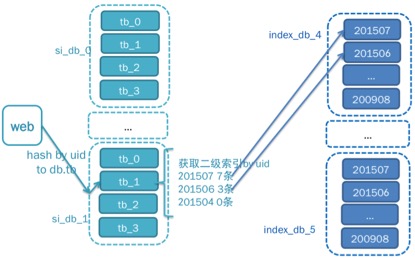
-
5. 当一台服务器宕机怎么办?
-
Slave(一主多从)宕机?
-
剩余健康Slave无风险,则无需紧急操作,例行修复
-
切换流量到容灾机房(如果具备容灾机房)
-
紧急扩容[优先]、重启、替换
- 有损降级部分请求
-
-
Master宕机?
-
由于master数据的唯一性,致使master出现异常会直接造成数据写入失败

-
-
快速下线master
-
下线一台salve的读服务(如果slave性能有风险,则同时快速扩容)
-
提升slave为master
- 生效新master与slave的同步机制
-
6. 如此复杂的分布式数据库+数据库拆分+数据表拆分,client端如何便捷操作呢?
多数使用分布式数据库服务的团队,都有各自实现的数据库Client组件,微博平台采用如下几个层级的组建来进行分布式数据库操作
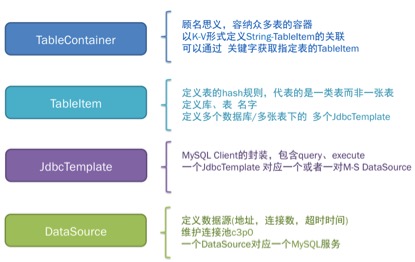
- 获取TableContainer,获取所有表定义规则
- 通过table name从TableContainer中获取指定的TableItem
- TableItem关联多个JdbcTeplate-DataSource
- 通过TableItem结合uid、id、date获取经过hash计算得到正确的JdbcTemplate及SQL
- 使用JdbcTemplate进行SQL操作
7. 注意事项
-
MySQL设计应该注意的问题
-
表字符集选择UTF8
-
存储引擎使用InnoDB
-
使用Varchar/Varbinary存储变长字符串
-
不在数据库中存储图片、文件等
-
每张表数据量控制在20000W以下
- 提前对业务做好垂直拆分
-
-
MySQL查询应该遇到的问题
-
-
避免使用存储过程、触发器、函数等
-
-
让数据库做最擅长的事
- 降低业务耦合度避开服务端BUG
-
-
避免使用大表的JOIN
-
-
MySQL最擅长的是单表的主键/索引查询
- JOIN消耗较多内存,产生临时表
-
-
避免在数据库中进行数学运算
-
-
MySQL不擅长数学运算
- 无法使用索引
-
-
减少与数据库的交互次数
-
-
select条件查询要利用索引
- 同一字段的条件判定要用in而不要用or
-
-
8. MySQL练习题
-
设计一个每秒2000qps,1亿条数据的用户基本信息存储数据库。完成数据库设计,数据库搭建,web写入查询服务搭建。
-
定义用户信息结构:uid,name,age,gender

-
给定2个mysql实例,每个实例创建2个数据库
-
每个数据库创建2长表
- 编写代码,以hash形式,实现对数据库、表的数据操作
四、Redis与Redis分布式架构设计
微博作为web2.0时代具备代表性的SNS服务,具备庞大的用户群体和亿级的活跃用户,同时也承担着高并发、低延迟的服务性能压力。
Redis作为NoSQL系列的一个典型应用,以其高成熟度、高可用性、高性能而被用来解决web2.0时代关系型数据库性能瓶颈问题。例如微博的计数服务的请求量以达到百万级/s,数以百计的关系型数据库才能应对如此高的QPS,而且请求耗时较高且波动较大;然而使用Redis这种NoSQL产品,仅仅需要10台级别的集群即可应对,平均请求耗时5ms以下。
这一章节,为大家介绍Redis以及其大规模集群架构。
1. Redis简介
-
Redis是一个支持内存存储及持久化存储的K-V存储系统
-
支持复杂数据结构,相比与Memcached仅支持简单的key-value存储,Redis原生支持几类常用的存储结构,例如
-
-
hash:存储哈希结构数据
- list:存储列表数据
-
-
单线程
-
高性能,避免过多考虑并发、锁、上下文切换
-
数据一致性好,例如对一个计数的并发操作,不会有‘读者写者’问题
-
单线程无法利用多核,单可以通过启动多个实例方式,充分利用多核
-
原生支持Master-Slave
-
过期机制
-
被动过期——client访问key时,判断过期时间选择是否过期
-
主动过期——默认使用valatile-lru
-
-
volatile-lru:从已设置过期时间的数据集中挑选最近最少使用的数据淘汰
-
volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰
-
volatile-random:从已设置过期时间的数据集中任意选择数据淘汰
-
allkeys-lru:从全部数据集中挑选最近最少使用的数据淘汰
- allkeys-random:从全部数据集中任意选择数据淘汰no-enviction(驱逐):禁止驱逐数据
-
-
Redis的字典表结构
-
-

-
Key字典表hash table结构,有hash结构就意味着需要按需进行rehash,rehash的时间段内,对内存是有成倍开销的
-
Value结构,存储Key对应的value
-
Expire表结构,存储key的过期时间
-
额外开销60B+
-
持久化方式
-
-
AOF
- Snapshot——RDB文件快照
-
-
-
与MC的差异
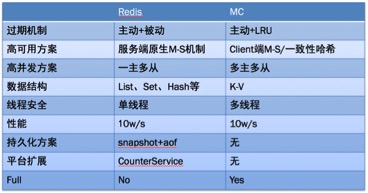
-
平台的定制CounterService
-
-
修改hash table为,增量扩展式的hash tables,例如每1亿个key存储在一个table中,数据超过1亿(或者一个临界比例)则开辟下一个1亿空间的table
- 废弃expire,Redis的主动过期策略无法像MC的LRU策略确保热数据留存在内存中,冷数据从缓存剔除,我们多数场景需要控制Redis中的数据量不突破内存限制
-
2. Redis的主要数据结构
-
String (key-value)
-
Hash (key-field-value)
-
List(key-values)
-
Set(key-members)
- SortedSet(key-member-score)
3. Redis的分布式部署方案是怎样的?与MySQL有什么异同
-
Reids由于其M-S特性与MySQL类似,因此分布式部署方案同MySQL相当
-
单实例——小型业务 or 业务初期
-
主从——HA、读写分离
-
一主多从——读取性能出现瓶颈
-
数据水平拆分——容量不足|写入性能瓶颈
-
常用的分布式部署方案

4. 分布式Redis架构如何实现高可用(HA)?
-
采用M-S高可用方案,原因也式由于其Master-Slave的特性
- 服务域名化是必要的,目前大型的Redis集群应用大多采用域名方式
5. 基本容量规划
-
空间=key数量*单条占用(K-V占用+额外空间) 用户空间=5亿用户*200B(平均)=100G 微博计数器=(500亿+预期2年新增300亿)*10B=800G
- 访问量=服务访问量*单次访问对资源的hit量 微博计数器Feed访问量=10000/s * 20 = 20万/s
6. CounterService
微博具备庞大的数据基数,因此所需要存储的数据量级也极其庞大
例如微博计数器,具有百亿条纪录,全部存储在Redis中,需要T级别的空间,成本过高
因此我们对Redis进行定制化改造,以使其适合多数数据小,大小有固定限制的数据
-
优化存储空间
-
采用分段哈希桶的形式,进行存储,避免rehash (分段存储要求key为递增序)

-
空间占用优化效果
-
key:8B
- value:自定义
7. 如何支持上述分布式架构下的client访问?(redis3.0+支持Redis Cluster)
-
Reids具有多个开源的client支持,我们所使用的是Jedis
-
Jedis除了提供client外,还提供了操作封装以及M-S组件
-
我们所使用的Redis系列组件如下:
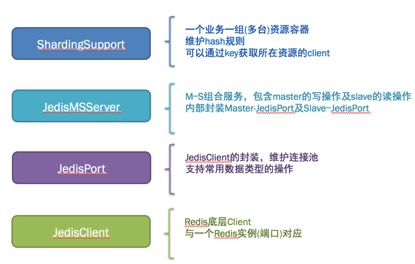
8. Redis练习题
-
使用Redis,实现用户受到的赞列表及赞计数功能
-
使用测试环境,启动两个Redis实例
-
使用Redis存储用户受到的赞列表[{uid, time}..]及赞计数uid-count
- 完成赞操作业务逻辑,包括赞、取消赞、查看赞列表、查看赞计数
五、思考与讨论
1. Memcache当容量到达瓶颈会 截取LRU链以释放空间。上文介绍过Redis的key过期机制,思考以下几个问题:
-
Redis满了会发生什么?如何避免发生上述问题呢?
- 为什么我们的定制Redis会废弃expire表?
2. MySQL与Redis各自适合什么样的场景?
-
数据冷热?
-
数据大小?
-
数据量级?
-
数据增长速度?
-
是否持久化?
-
访问量(read/write)?
-
请求性能要求?
-
新兵训练营简介
微博平台新兵训练营活动是微博平台内部组织的针对新入职同学的团队融入培训课程,目标是团队融入,包括人的融入,氛围融入,技术融入。当前已经进行4期活动,很多学员迅速成长为平台技术骨干。
微博平台是非常注重团队成员融入与成长的团队,在这里有人帮你融入,有人和你一起成长,也欢迎小伙伴们加入微博平台,欢迎私信咨询。
讲师简介
毕建坤,@bijiankun 微博平台及大数据部——平台研发系统研发工程师,2012年7月毕业于哈尔滨理工大学,校招入职微博工作至今,先后负责微博Feed、赞、评论等底层服务研发以及方案评审等工作。聚焦大规模系统的架构设计与优化,以及大规模系统下的服务稳定性保障。新兵训练营第一期学员。


更多建议: