


OpenAI API 快速开始
OpenAI 训练了非常擅长理解和生成文本的尖端语言模型。我们的 API 提供对这些模型的访问,可用于解决几乎任何涉及处理语言的任务。
在本快速入门教程中,您将构建一个简单的示例应用程序。在此过程中,您将学习使用 API 完成任何任务的关键概念和技术,包括:
内容生成
- 归纳
分类、分类和情感分析
数据提取
- 翻译
- 更多
介绍
完成端点是我们 API 的核心,它提供了一个非常灵活和强大的简单接口。您输入一些文本作为提示,API 将返回一个文本完成,试图匹配您提供的任何指令或上下文。

您可以将其视为非常高级的自动完成——模型处理您的文本提示并尝试预测接下来最有可能出现的内容。
从指令开始
假设您想创建一个宠物名字生成器。从头开始想出名字很难!
首先,您需要一个明确说明您想要什么的提示。让我们从一个指令开始。提交此提示以生成您的第一个完成。
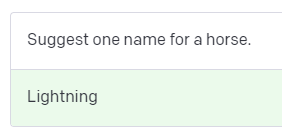
不错!现在,试着让你的指示更具体。

如您所见,在我们的提示中添加一个简单的形容词会改变生成的完成。设计提示本质上就是您“编程”模型的方式。
添加一些例子
制定好的说明对于取得好的结果很重要,但有时它们还不够。让我们试着让你的指令更复杂。

这个完成并不是我们想要的。这些名称非常通用,而且模型似乎没有接受我们指令中的马匹部分。让我们看看能否让它提出一些更相关的建议。
在许多情况下,向模型展示和告诉模型您想要什么是很有帮助的。在您的提示中添加示例可以帮助传达模式或细微差别。尝试提交此提示,其中包含几个示例。

好的!添加我们期望给定输入的输出示例有助于模型提供我们正在寻找的名称类型。
调整您的设置
提示设计并不是您可以使用的唯一工具。您还可以通过调整设置来控制完成。最重要的设置之一称为温度。
您可能已经注意到,如果您在上面的示例中多次提交相同的提示,模型将始终返回相同或非常相似的完成。这是因为您的温度设置为 0。
尝试将温度设置为 1 重新提交几次相同的提示。


看看发生了什么?当温度高于 0 时,每次提交相同的提示会导致不同的完成。
请记住,该模型预测哪个文本最有可能跟在它前面的文本之后。温度是一个介于 0 和 1 之间的值,基本上可以让您控制模型在进行这些预测时的置信度。降低温度意味着它将承担更少的风险,并且完成将更加准确和确定。升高温度将导致更多样化的完成。
了解 tokens 和 probabilities
我们的模型通过将文本分解为更小的单元(称为标记)来处理文本。标记可以是单词、单词块或单个字符。编辑下面的文本以查看它是如何被标记化的。
I have an orange cat named Butterscotch.
像“猫”这样的常用词是单个标记,而不太常用的词通常被分解成多个标记。例如,“Butterscotch”翻译成四个标记:“But”、“ters”、“cot”和“ch”。许多标记以空格开头,例如“hello”和“bye”。
给定一些文本,该模型确定下一个最有可能出现的标记。例如,文本“Horses are my favorite”最有可能跟随标记“animal”。

这是 temperature 发挥作用的地方。如果您在 temperature 为 0 的情况下提交此提示 4 次,则模型将始终在下一个返回“animal”,因为它的概率最高。如果你提高 temperature,它会承担更多的风险,并考虑概率较低的 tokens。
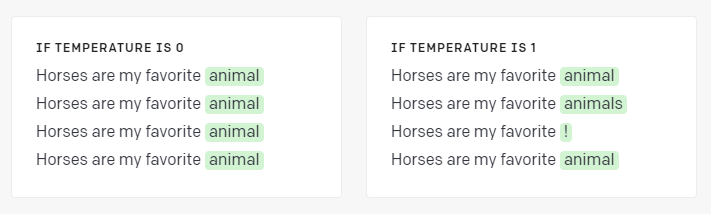
通常最好为所需输出明确定义的任务设置低 temperature。较高的 temperature 对于需要多样性或创造力的任务可能很有用,或者如果您想为最终用户或人类专家生成一些变化以供选择。
对于您的昵称生成器,您可能希望能够生成很多名字创意。 0.6 的适中 temperature 应该可以正常工作。
构建您的应用程序
- Node.JS
现在你已经找到了一个好的提示和设置,你已经准备好构建你的宠物名称生成器了!我们已经编写了一些代码来帮助您入门——按照下面的说明下载代码并运行应用程序。
设置
确保已经安装 Node.js。然后克隆该仓库
git clone https://github.com/openai/openai-quickstart-node.git如果您不想使用 git,您也可以使用此 zip 文件下载代码。
添加您的 API 密钥
导航到项目目录并复制示例环境变量文件。
cd openai-quickstart-node
cp .env.example .env复制您的 API 密钥并将其设置为新创建的 .env 文件中的 OPENAI_API_KEY。
重要说明:使用 Javascript 时,所有 API 调用都应仅在服务器端进行,因为在客户端浏览器代码中进行调用会暴露您的 API 密钥。
运行应用
在项目目录下运行以下命令安装依赖并运行应用程序。
npm install
npm run dev在浏览器中打开 http://localhost:3000,您应该会看到宠物名称生成器!
理解代码
在 openai-quickstart-node/pages/api 文件夹中打开 generate.js。在底部,您会看到生成我们在上面使用的提示的函数。由于用户将输入他们宠物的动物类型,因此它会动态换出指定动物的提示部分。
function generatePrompt(animal) {
const capitalizedAnimal = animal[0].toUpperCase() + animal.slice(1).toLowerCase();
return `Suggest three names for an animal that is a superhero.
Animal: Cat
Names: Captain Sharpclaw, Agent Fluffball, The Incredible Feline
Animal: Dog
Names: Ruff the Protector, Wonder Canine, Sir Barks-a-Lot
Animal: ${capitalizedAnimal}
Names:`;
}在 generate.js 的第 9 行,您将看到发送实际 API 请求的代码。如上所述,它使用 temperature 为 0.6 的完成端点。
const completion = await openai.createCompletion({
model: "text-davinci-003",
prompt: generatePrompt(req.body.animal),
temperature: 0.6,
});就是这样!您现在应该完全了解您的宠物名称生成器如何使用 OpenAI API!
设置
确保已经安装 Python。然后克隆该仓库
git clone https://github.com/openai/openai-quickstart-python.git如果您不想使用 git,您也可以使用此 zip 文件下载代码。
添加您的 API 密钥
导航到项目目录并复制示例环境变量文件。
cd openai-quickstart-python
cp .env.example .env复制您的 API 密钥并将其设置为新创建的 .env 文件中的 OPENAI_API_KEY。
运行应用
在项目目录下运行以下命令安装依赖并运行应用程序。运行命令时,您可能需要键入 python3/pip3 而不是 python/pip,具体取决于您的设置。
python -m venv venv
. venv/bin/activate
pip install -r requirements.txt
flask run在浏览器中打开 http://localhost:5000,您应该会看到宠物名称生成器!
理解代码
在 openai-quickstart-python 文件夹中打开 app.py。在底部,您会看到生成我们在上面使用的提示的函数。由于用户将输入他们宠物的动物类型,因此它会动态换出指定动物的提示部分。
def generate_prompt(animal):
return """Suggest three names for an animal that is a superhero.
Animal: Cat
Names: Captain Sharpclaw, Agent Fluffball, The Incredible Feline
Animal: Dog
Names: Ruff the Protector, Wonder Canine, Sir Barks-a-Lot
Animal: {}
Names:""".format(animal.capitalize())在 app.py 的第 14 行,您将看到发送实际 API 请求的代码。如上所述,它使用 temperature 为 0.6 的完成端点。
response = openai.Completion.create(
model="text-davinci-003",
prompt=generate_prompt(animal),
temperature=0.6
)就是这样!您现在应该完全了解您的宠物名称生成器如何使用 OpenAI API!
Closing
这些概念和技术将大大有助于您构建自己的应用程序。也就是说,这个简单的例子只是展示了可能性的一小部分!完成端点非常灵活,几乎可以解决任何语言处理任务,包括内容生成、摘要、语义搜索、主题标记、情感分析等等。
要记住的一个限制是,对于大多数模型,单个 API 请求在提示和完成之间最多只能处理 2,048 个标记(大约 1,500 个单词)。
模型和价格
我们提供一系列具有不同功能和价位的型号。在本教程中,我们使用了我们最强大的自然语言模型 text-davinci-003。我们建议在试验时使用此模型,因为它会产生最佳结果。一旦一切正常,您就可以查看其他模型是否可以以更低的延迟和成本产生相同的结果。
单个请求(提示和完成)中处理的令牌总数不能超过模型的最大上下文长度。对于大多数模型,这是 2,048 个标记或大约 1,500 个单词。根据粗略的经验法则,对于英文文本,1 个标记大约为 4 个字符或 0.75 个单词。
对于更高级的任务,您可能会发现自己希望能够提供更多的示例或上下文,而不是单个提示中的内容。fine-tuning API 是执行此类更高级任务的绝佳选择。微调允许您提供数百甚至数千个示例来为您的特定用例定制模型。


更多建议: