
 免费 AI IDE
免费 AI IDE

OceanBase 层次查询
层次查询(Hierarchical Query)是一种具有特殊功能的查询语句,通过它能够将分层数据按照层次关系展示出来。分层数据是指关系表中的数据之间具有层次关系。这种关系在现实生活中十分常见,例如:
-
组织架构中组长和组员之间的关系。
-
企业中上下级部门之间的关系。
-
Web 网页中,页面跳转的关系。
语法
SELECT [level], column, expr... FROM table [WHERE condition] [ START WITH start_expression ]
CONNECT BY [NOCYCLE] { PRIOR child_expr = parent_expr | parent_expr = PRIOR child_expr }
[ ORDER SIBLINGS BY …] [ GROUP BY … ] [ HAVING … ] [ ORDER BY … ]参数
|
参数 |
说明 |
|---|---|
|
LEVEL |
节点的层次,是伪列,表示等级。由查询的起点开始算起为 1,依次类推。 |
|
CONNECT_BY_ISLEAF |
当前数据行是否是层次关系中的叶子节点,是伪列,0表示不是,1表示是。 |
|
CONNECT_BY_ISCYCLE |
当前数据行是否在循环中,是伪列,0表示不是,1表示是。 |
|
CONNECT_BY_ROOT运算符 |
CONNECT_BY_ROOT是一元运算符,表示参数中的列来自于层次查询的根节点,与一元的 + 和 - 具有相同的优先级。 |
|
condition |
条件。 |
|
CONNECT BY |
指明如何来确定父子关系,这里通常使用等值表达式,但其他表达式同样支持。 |
|
START WITH |
指明层次查询中的根行(Root row)。 |
|
PRIOR 运算符 |
PRIOR 是一元运算符,表示参数中的列来自于父行(Parent row),与一元的 + 和 - 具有相同的优先级。 |
|
NOCYCLE |
当指定该关键字时,即使返回结果中有循环仍旧可以返回,并可以通过 |
|
ORDER SIBLINGS BY |
指定同一个层级行之间的排列顺序。 |
执行流程
使用和实现层次查询最关键是要理解其执行流程,层次查询执行流程:
-
执行
FROM后面的SCAN或JOIN操作; -
根据
START WITH和CONNECT BY的内容生成层次关系结果; -
按照常规查询执行流程执行剩下的子句(例如
WHERE、GROUP、ORDER BY......)对于 2 中生成层次关系的流程可以理解为: -
根据
START WITH中的表达式得到根行(Root rows)。 -
根据
CONNECT BY中的表达式 选择每个根行(Root rows)的子行(Child rows)。 -
将 2 中生成的子行(Child rows)作为新的根行(Root rows)进一步生成子行(Child rows),周而复始直到没有新行生成。
示例
展示层次查询的使用,向表 emp中的 emp_id、position 和 mgr_id 列插入数据。执行以下语句:
CREATE TABLE emp(emp_id INT,position VARCHAR(50),mgr_id INT);
INSERT INTO emp VALUES (1,'全球经理',NULL);
INSERT INTO emp VALUES (2,'欧洲区经理',1);
INSERT INTO emp VALUES (3,'亚太区经理',1);
INSERT INTO emp VALUES (4,'美洲区经理',1);
INSERT INTO emp VALUES (5,'意大利区经理',2);
INSERT INTO emp VALUES (6,'法国区经理',2);
INSERT INTO emp VALUES (7,'中国区经理',3);
INSERT INTO emp VALUES (8,'韩国区经理',3);
INSERT INTO emp VALUES (9,'日本区经理',3);
INSERT INTO emp VALUES (10,'美国区经理',4);
INSERT INTO emp VALUES (11,'加拿大区经理',4);
INSERT INTO emp VALUES (12,'北京区经理',7);通过上面的内容可以看见列 position 具有清晰的层次关系。树状结构如下:
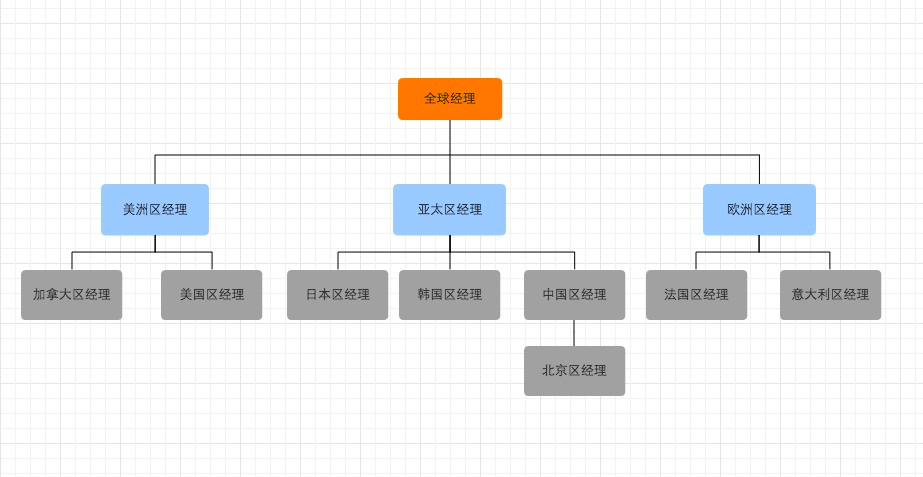
是按照层次结构将结果展示出来,执行以下语句:
SELECT emp_id, mgr_id, position, level FROM emp
START WITH mgr_id IS NULL CONNECT BY PRIOR emp_id = mgr_id;查询结果如下:
+--------+--------+-------------------+-------+
| EMP_ID | MGR_ID | POSITION | LEVEL |
+--------+--------+-------------------+-------+
| 1 | NULL| 全球经理 | 1 |
| 2 | 1 | 欧洲区经理 | 2 |
| 5 | 2 | 意大利区经理 | 3 |
| 6 | 2 | 法国区经理 | 3 |
| 3 | 1 | 亚太区经理 | 2 |
| 7 | 3 | 中国区经理 | 3 |
| 12 | 7 | 北京区经理 | 4 |
| 8 | 3 | 韩国区经理 | 3 |
| 9 | 3 | 日本区经理 | 3 |
| 4 | 1 | 美洲区经理 | 2 |
| 10 | 4 | 美国区经理 | 3 |
| 11 | 4 | 加拿大区经理 | 3 |
+--------+--------+-------------------+-------+如果仅查询“亚太区”的层次结构,执行以下语句:
SELECT emp_id, mgr_id, position, level FROM emp START WITH position = '亚太区经理' CONNECT BY PRIOR emp_id = mgr_id;查询结果如下:
+--------+--------+----------------+-------+
| EMP_ID | MGR_ID | POSITION | LEVEL |
+--------+--------+----------------+-------+
| 3 | 1 | 亚太区经理 | 1 |
| 7 | 3 | 中国区经理 | 2 |
| 12 | 7 | 北京区经理 | 3 |
| 8 | 3 | 韩国区经理 | 2 |
| 9 | 3 | 日本区经理 | 2 |
+--------+--------+----------------+-------+

更多建议: