
 免费 AI IDE
免费 AI IDE
六、遇到的一些坑和问题
遇到的一些坑和问题
SSD性能差
使用SSD做KV存储时发现磁盘IO非常低。配置成RAID10的性能只有3~6MB/s;配置成RAID0的性能有~130MB/s,系统中没有发现CPU,MEM,中断等瓶颈。一台服务器从RAID1改成RAID0后,性能只有~60MB/s。这说明我们用的SSD盘性能不稳定。
根据以上现象,初步怀疑以下几点:SSD盘,线上系统用的三星840Pro是消费级硬盘。RAID卡设置,Write back和Write through策略。后来测试验证,有影响,但不是关键。RAID卡类型,线上系统用的是LSI 2008,比较陈旧。
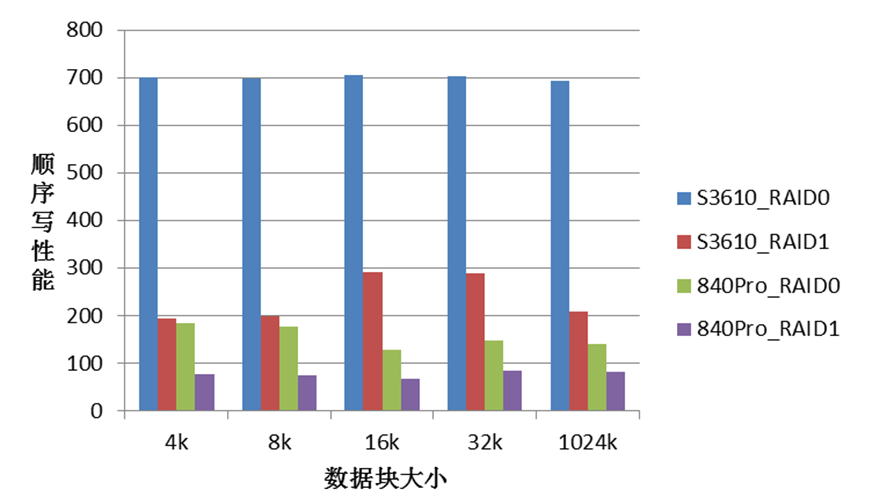
本实验使用dd顺序写操作简单测试,严格测试需要用FIO等工具。
键值存储选型压测
我们对于存储选型时尝试过LevelDB、RocksDB、BeansDB、LMDB、Riak等,最终根据我们的需求选择了LMDB。
机器:2台
配置:32核CPU、32GB内存、SSD((512GB)三星840Pro--> (600GB)Intel 3500 /Intel S3610)
数据:1.7亿数据(800多G数据)、大小5~30KB左右
KV存储引擎:LevelDB、RocksDB、LMDB,每台启动2个实例
压测工具:tcpcopy直接线上导流
压测用例:随机写+随机读
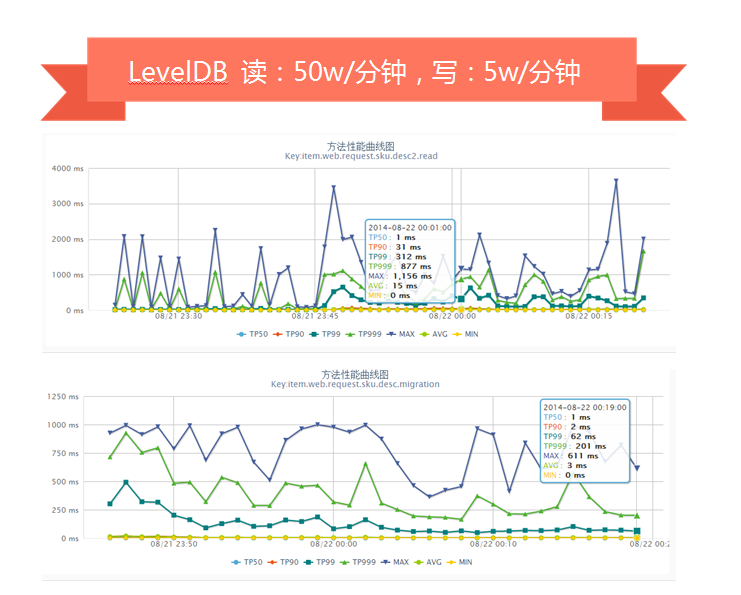
LevelDB压测时,随机读+随机写会产生抖动(我们的数据出自自己的监控平台,分钟级采样)。
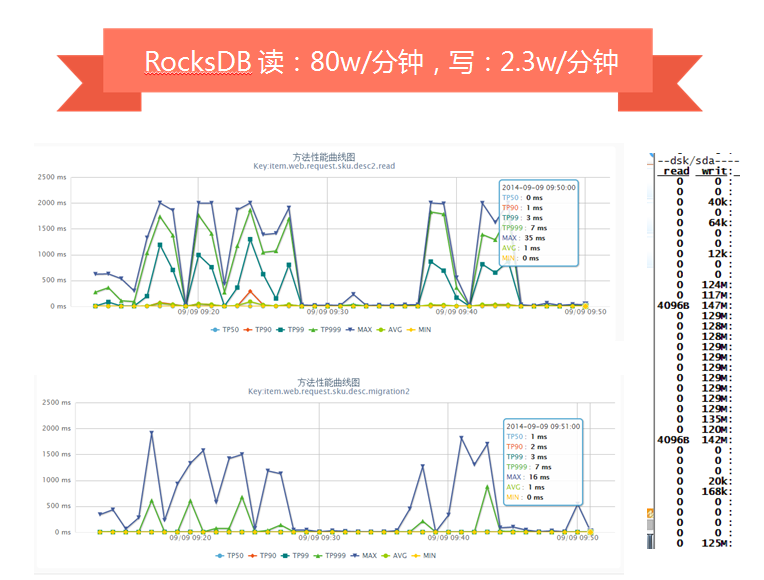
RocksDB是改造自LevelDB,对SSD做了优化,我们压测时单独写或读,性能非常好,但是读写混合时就会因为归并产生抖动。
LMDB引擎没有大的抖动,基本满足我们的需求。
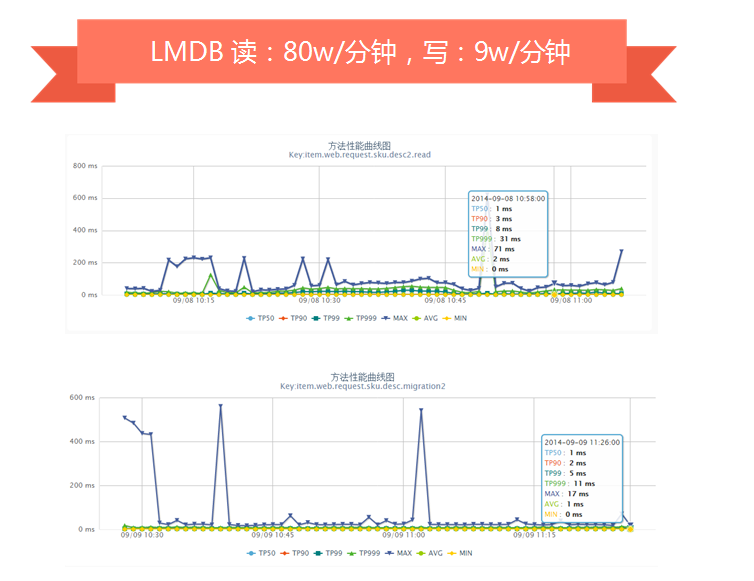
我们目前一些线上服务器使用的是LMDB,其他一些正在尝试公司自主研发的CycleDB引擎。
数据量大时JIMDB同步不动
Jimdb数据同步时要dump数据,SSD盘容量用了50%以上,dump到同一块磁盘容量不足。解决方案:
1、一台物理机挂2块SSD(512GB),单挂raid0;启动8个jimdb实例;这样每实例差不多125GB左右;目前是挂4块,raid0;新机房计划8块raid10;
2、目前是千兆网卡同步,同步峰值在100MB/s左右;
3、dump和sync数据时是顺序读写,因此挂一块SAS盘专门来同步数据;
4、使用文件锁保证一台物理机多个实例同时只有一个dump;
5、后续计划改造为直接内存转发而不做dump。
切换主从
之前存储架构是一主二从(主机房一主一从,备机房一从)切换到备机房时,只有一个主服务,读写压力大时有抖动,因此我们改造为之前架构图中的一主三从。
分片配置
之前的架构是分片逻辑分散到多个子系统的配置文件中,切换时需要操作很多系统;解决方案:
1、引入Twemproxy中间件,我们使用本地部署的Twemproxy来维护分片逻辑;
2、使用自动部署系统推送配置和重启应用,重启之前暂停mq消费保证数据一致性;
3、用unix domain socket减少连接数和端口占用不释放启动不了服务的问题。
模板元数据存储HTML
起初不确定Lua做逻辑和渲染模板性能如何,就尽量减少for、if/else之类的逻辑;通过java worker组装html片段存储到jimdb,html片段会存储诸多问题,假设未来变了也是需要全量刷出的,因此存储的内容最好就是元数据。因此通过线上不断压测,最终jimdb只存储元数据,lua做逻辑和渲染;逻辑代码在3000行以上;模板代码1500行以上,其中大量for、if/else,目前渲染性能可以接受。
线上真实流量,整体性能从TP99 53ms降到32ms。
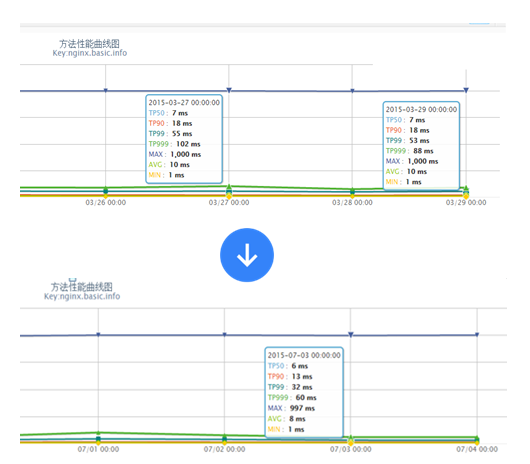
绑定8 CPU测试的,渲染模板的性能可以接受。
库存接口访问量600w/分钟
商品详情页库存接口2014年被恶意刷,每分钟超过600w访问量,tomcat机器只能定时重启;因为是详情页展示的数据,缓存几秒钟是可以接受的,因此开启nginx proxy cache来解决该问题,开启后降到正常水平;我们目前正在使用Nginx+Lua架构改造服务,数据过滤、URL重写等在Nginx层完成,通过URL重写+一致性哈希负载均衡,不怕随机URL,一些服务提升了10%+的缓存命中率。
微信接口调用量暴增
通过访问日志发现某IP频繁抓取;而且按照商品编号遍历,但是会有一些不存在的编号;解决方案:
1、读取KV存储的部分不限流;
2、回源到服务接口的进行请求限流,保证服务质量。
开启Nginx Proxy Cache性能不升反降
开启Nginx Proxy Cache后,性能下降,而且过一段内存使用率到达98%;解决方案:
1、对于内存占用率高的问题是内核问题,内核使用LRU机制,本身不是问题,不过可以通过修改内核参数
sysctl -w vm.extra_free_kbytes=6436787
sysctl -w vm.vfs_cache_pressure=10000
2、使用Proxy Cache在机械盘上性能差可以通过tmpfs缓存或nginx共享字典缓存元数据,或者使用SSD,我们目前使用内存文件系统。
配送至读服务因依赖太多,响应时间偏慢
配送至服务每天有数十亿调用量,响应时间偏慢。解决方案:
1、串行获取变并发获取,这样一些服务可以并发调用,在我们某个系统中能提升一倍多的性能,从原来TP99差不多1s降到500ms以下;
2、预取依赖数据回传,这种机制还一个好处,比如我们依赖三个下游服务,而这三个服务都需要商品数据,那么我们可以在当前服务中取数据,然后回传给他们,这样可以减少下游系统的商品服务调用量,如果没有传,那么下游服务再自己查一下。
假设一个读服务是需要如下数据:
1、数据A 10ms
2、数据B 15ms
3、数据C 20ms
4、数据D 5ms
5、数据E 10ms
那么如果串行获取那么需要:60ms;
而如果数据C依赖数据A和数据B、数据D谁也不依赖、数据E依赖数据C;那么我们可以这样子来获取数据:

那么如果并发化获取那么需要:30ms;能提升一倍的性能。
假设数据E还依赖数据F(5ms),而数据F是在数据E服务中获取的,此时就可以考虑在此服务中在取数据A/B/D时预取数据F,那么整体性能就变为了:25ms。
通过这种优化我们服务提升了差不多10ms性能。
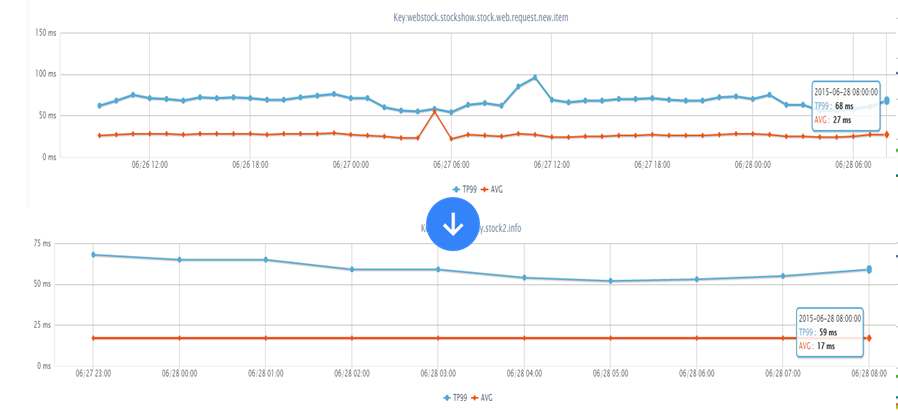
如下服务是在抖动时的性能,老服务TP99 211ms,新服务118ms,此处我们主要就是并发调用+超时时间限制,超时直接降级。
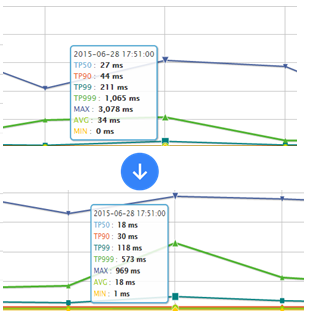
网络抖动时,返回502错误
Twemproxy配置的timeout时间太长,之前设置为5s,而且没有分别针对连接、读、写设置超时。后来我们减少超时时间,内网设置在150ms以内,当超时时访问动态服务。
机器流量太大
2014年双11期间,服务器网卡流量到了400Mbps,CPU 30%左右。原因是我们所有压缩都在接入层完成,因此接入层不再传入相关请求头到应用,随着流量的增大,接入层压力过大,因此我们把压缩下方到各个业务应用,添加了相应的请求头,Nginx GZIP压缩级别在2~4吞吐量最高;应用服务器流量降了差不多5倍;目前正常情况CPU在4%以下。



更多建议: