
 免费 AI IDE
免费 AI IDE
神经网络今天已经变得非常流行,但仍然缺乏对它们的了解。一方面,我们已经看到很多人无法识别各种类型的神经网络及其解决的问题,更不用说区分它们中的每一个了。其次,在某种程度上更糟糕的是,当人们在谈论任何神经网络时不加区分地使用深度学习这个词而没有打破差异。
在这篇文章中,我们将讨论每个人在从事 AI 研究时都应该熟悉的最流行的神经网络架构。
1. 前馈神经网络
这是最基本的神经网络类型,它在很大程度上是由于技术进步而产生的,它使我们能够添加更多隐藏层,而无需过多担心计算时间。由于Geoff Hinton 在 1990 年发现了反向传播算法,它也变得流行起来。
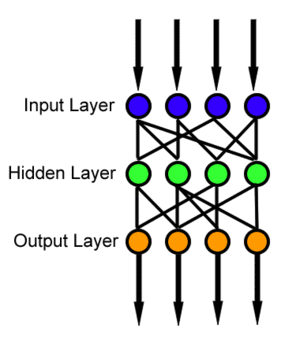
这种类型的神经网络本质上由一个输入层、多个隐藏层和一个输出层组成。没有循环,信息只向前流动。前馈神经网络通常适用于数值数据的监督学习,尽管它也有其缺点:
- 它不能与顺序数据一起使用。
- 它不适用于图像数据,因为该模型的性能严重依赖于特征,而手动查找图像或文本数据的特征本身就是一项非常困难的练习。
这将我们带到了接下来的两类神经网络:卷积神经网络和循环神经网络。
2. 卷积 神经网络(CNN)
在 CNN 流行之前,人们用于图像分类的算法有很多。人们过去常常从图像中创建特征,然后将这些特征输入到一些分类算法中,例如 SVM。一些算法也使用图像的像素级值作为特征向量。举个例子,您可以训练一个具有 784 个特征的 SVM,其中每个特征都是 28x28 图像的像素值。
为什么 CNN 以及为什么它们工作得更好?
CNN 可以被认为是图像中的自动特征提取器。虽然如果我使用带有像素向量的算法,我会失去很多像素之间的空间交互,而 CNN 有效地使用相邻像素信息首先通过卷积有效地对图像进行下采样,然后在最后使用预测层。
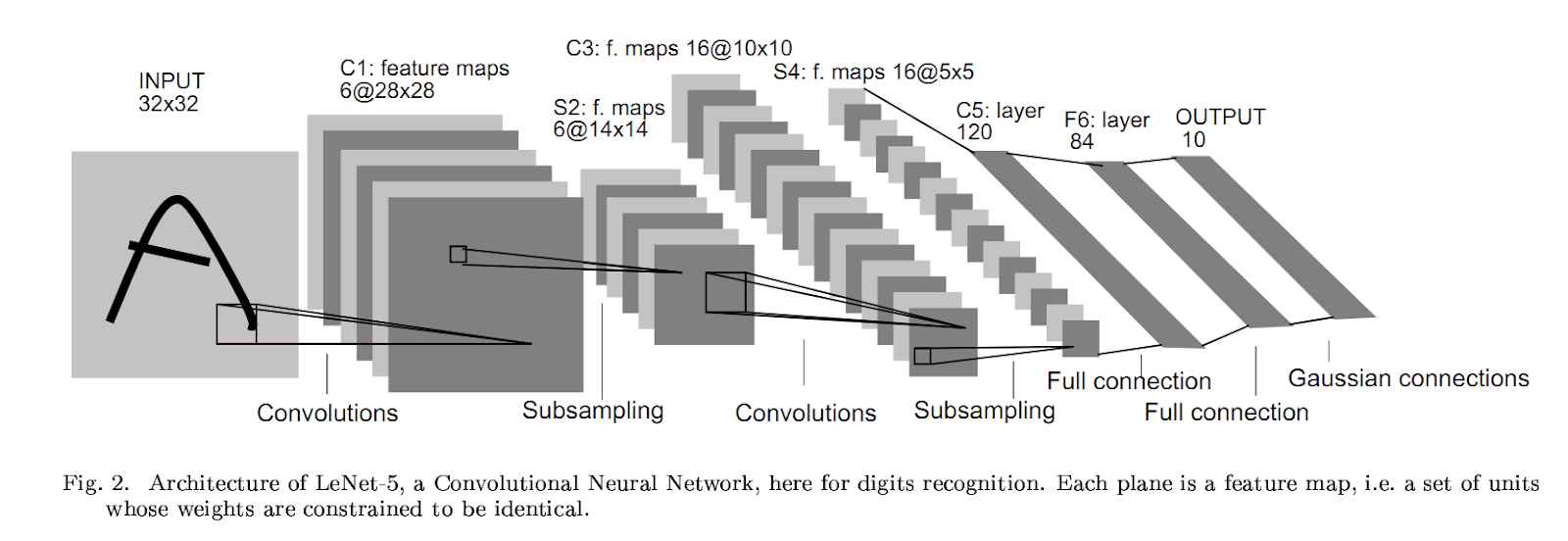
这个概念最初由 Yann le cun 在 1998 年提出,用于数字分类,他使用单个卷积层来预测数字。它后来在 2012 年被 Alexnet 推广,它使用多个卷积层在 Imagenet 上实现最先进的预测。从而使它们成为今后图像分类挑战的首选算法。
随着时间的推移,在这个特定领域取得了各种进步,研究人员为 CNN 提出了各种架构,如 VGG、Resnet、Inception、Xception 等,这些架构不断推动图像分类的最新技术发展。

相比之下,CNN 也用于对象检测,这可能是一个问题,因为除了对图像进行分类之外,我们还想检测图像中各种对象周围的边界框。过去,研究人员提出了许多架构,如 YOLO、RetinaNet、Faster RCNN 等来解决对象检测问题,所有这些架构都使用 CNN 作为其架构的一部分。
3. 循环神经网络(LSTM/GRU/Attention)
CNN 对于图像意味着什么,循环神经网络对于文本意味着什么。RNN 可以帮助我们学习文本的顺序结构,其中每个词都依赖于前一个词或前一个句子中的一个词。
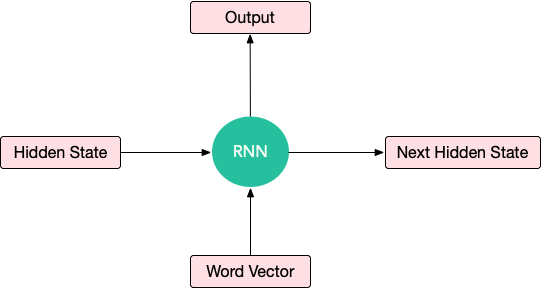
对于 RNN 的简单解释,将 RNN 单元视为一个黑盒子,输入一个隐藏状态(一个向量)和一个词向量,并给出一个输出向量和下一个隐藏状态。这个盒子有一些权重,需要使用损失的反向传播进行调整。此外,相同的单元格应用于所有单词,以便在句子中的单词之间共享权重。这种现象称为权重共享。
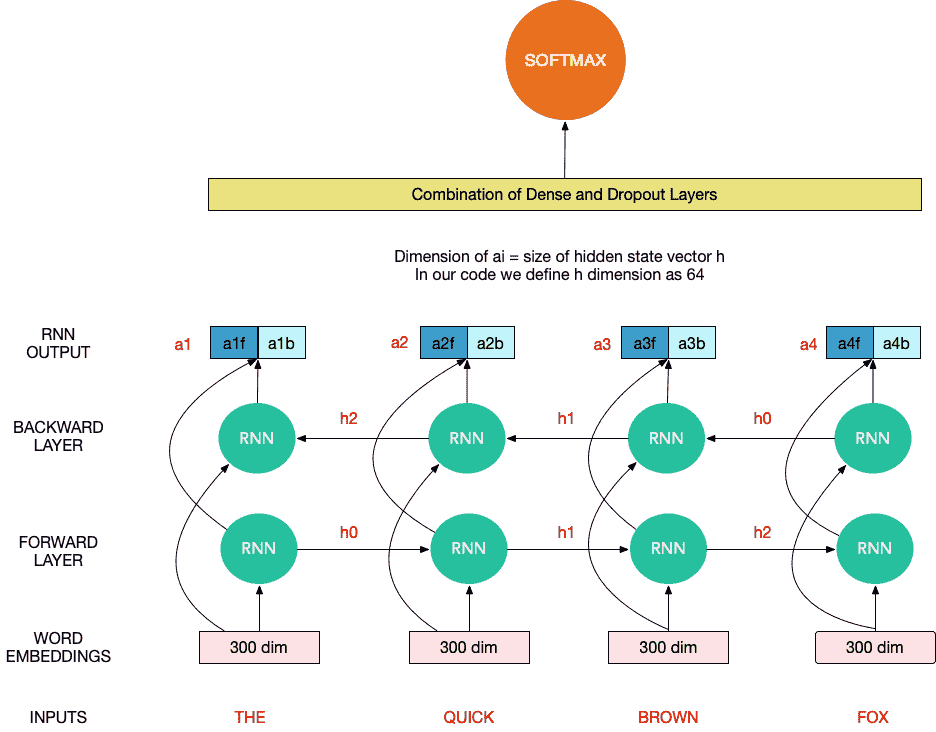
下面是相同 RNN 单元的扩展版本,其中每个 RNN 单元在每个单词标记上运行,并将隐藏状态传递给下一个单元。对于像“the quick brown fox”这样的长度为 4 的序列,RNN 单元最终给出了 4 个输出向量,这些向量可以连接起来,然后用作密集前馈架构的一部分,如下所示,以解决最终任务语言建模或分类任务:
长短期记忆网络 (LSTM) 和门控循环单元(GRU) 是 RNN 的一个子类,专门通过引入各种门来长时间记忆信息(也称为消失梯度问题),这些门通过添加或删除信息来调节细胞状态从中。
从一个非常高的角度来看,您可以将 LSTM/GRU 理解为在 RNN 单元上学习长期依赖关系的一种游戏。RNN/LSTM/GRU 主要用于各种语言建模任务,其目标是在给定输入词流的情况下预测下一个词,或者用于具有顺序模式的任务。如果您想学习如何将 RNN 用于文本分类任务,请查看这篇 文章。
接下来我们应该提到的是基于注意力的 模型,但我们在这里只讨论直觉,因为深入研究这些模型可以获得非常技术性的知识(如果有兴趣,您可以查看这篇 文章)。过去,使用TFIDF/CountVectorizer等传统方法通过关键字提取从文本中查找特征。有些词比其他词更有助于确定文本的类别。然而,在这种方法中,我们有点丢失了文本的顺序结构。使用 LSTM 和深度学习方法,我们可以处理序列结构,但我们失去了为更重要的单词赋予更高权重的能力。我们可以两全其美吗? 答案是肯定的。其实,注意力就是你所需要的 . 用作者的话来说:
“并非所有单词对句子含义的表示都有同样的贡献。因此,我们引入了一种注意力机制来提取对句子含义很重要的单词,并聚合这些信息单词的表示以形成句子向量。”
4. 变压器
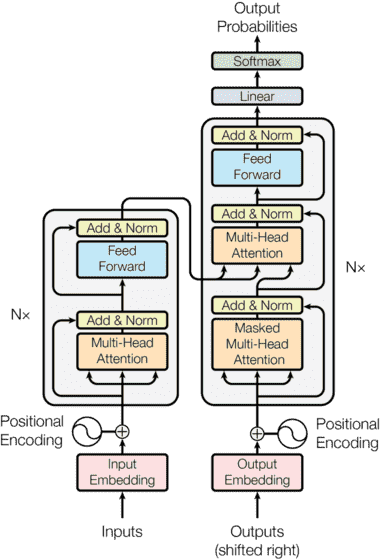
Transformer 已经成为任何自然语言处理 (NLP) 任务的事实上的标准,最近推出的 GPT-3 转换器是迄今为止最大的。
过去,LSTM 和 GRU 架构以及注意力机制曾经是语言建模问题和翻译系统的最先进方法。这些架构的主要问题是它们本质上是循环的,运行时间随着序列长度的增加而增加。也就是说,这些架构采用一个句子并以顺序方式处理每个单词,因此当句子长度增加时,整个运行时间也会增加。
Transformer,首先在论文中解释的模型架构 注意就是你所需要的,放弃这种循环,而是完全依赖于注意力机制来绘制输入和输出之间的全局依赖关系。这使得它更快、更准确,成为解决 NLP 领域各种问题的首选架构。
5. 生成对抗网络 (GAN)
数据科学领域的人们最近看到了很多 AI 生成的人,无论是在论文、博客还是视频中。我们已经到了一个阶段,区分真实的人脸和 人工智能生成的人脸变得越来越困难。而这一切都是通过 GAN 实现的。GAN 很可能会改变我们生成视频游戏和特效的方式。使用这种方法,您可以按需创建逼真的纹理或角色,打开一个充满可能性的世界。
GAN 通常使用两个决斗神经网络来训练计算机以足够好地学习数据集的性质以生成令人信服的假货。其中一个神经网络生成假图像(生成器),另一个神经网络尝试分类哪些图像是假的(鉴别器)。这些网络通过相互竞争而随着时间的推移而改进。
也许最好把发电机想象成一个强盗,把鉴别器想象成一个警察。强盗偷得越多,他偷东西的能力就越好。同时,警察也更擅长抓小偷。
这些神经网络中的损失主要取决于另一个网络的表现:
- 鉴别器网络损失是生成器网络质量的函数:如果鉴别器被生成器的假图像愚弄,它的损失会很高。
- 生成器网络损失是鉴别器网络质量的函数:如果生成器无法欺骗鉴别器,则损失很高。
在训练阶段,我们依次训练鉴别器和生成器网络,旨在提高两者的性能。最终目标是得到有助于生成器创建逼真图像的权重。最后,我们将使用生成器神经网络从随机噪声中生成高质量的假图像。
6. 自编码器
自编码器是 深度学习函数,它近似于从 X 到 X 的映射,即输入 = 输出。他们首先将输入特征压缩为低维表示 ,然后从该表示重构输出。
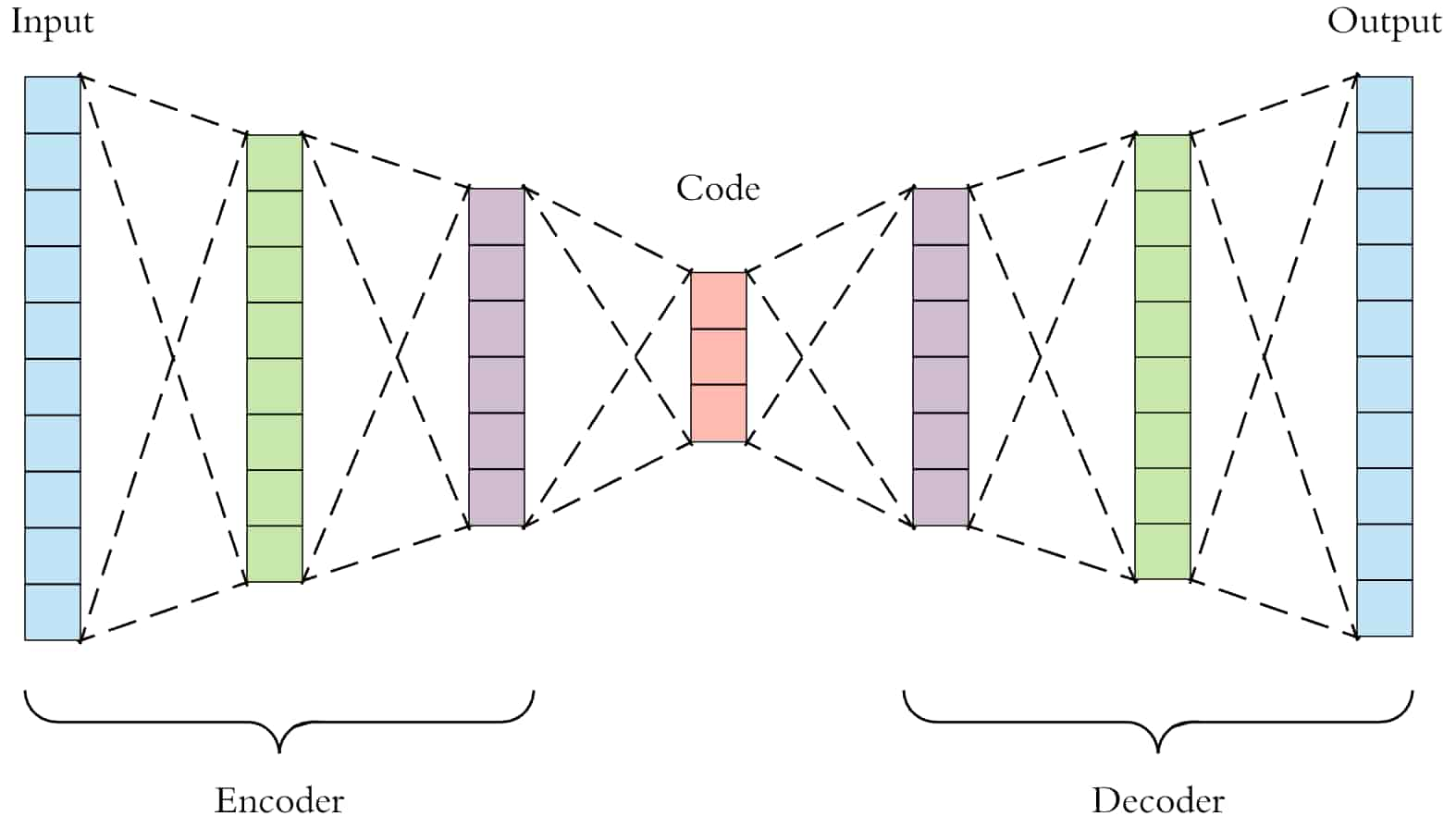
在很多地方,这个表示向量可以作为模型特征,从而用于降维。
自编码器也用于异常检测,我们尝试使用自编码器重建我们的示例,如果重建损失太高,我们可以预测该示例是异常。
结论
神经网络本质上是有史以来最伟大的模型之一,它们可以很好地概括我们能想到的大多数建模用例。如今,这些不同版本的神经网络正被用于解决医疗保健、银行和汽车行业等领域的各种重要问题,并被苹果、谷歌和 Facebook 等大公司用于提供推荐和帮助搜索查询. 例如,Google 使用 BERT,这是一个基于 Transformers 的模型来支持其搜索查询。



