
 免费 AI IDE
免费 AI IDE
本文转载至微信公众号「大数据前沿」,已获取授权
下载W3Cschool手机App,0基础随时随地学编程>>戳此了解
导言
二胖最近在逛京东的时候偶然发现:MM们购买bra的记录上竟然留下了尺寸和颜色等信息,我当时就想,要不要抓点数据下来看看啊
然后就有了这篇文章~~~
Let's go!
科普一下
在抓数据前,先给各位男性朋友科普一下,这个size信息到底怎么看(ps:我也是在网上查的(⊙o⊙)…)
70B,80C...到底啥意思?

数字的意思是下胸围,是水平围绕胸部底部一周的长度,即胸部下围尺寸,单位是厘米。
如果下胸围在68cm~72cm之间,那么就可以选择70码。
然后ABCDEFGH就是size了,请自行体会~~~
所以一个尺码是由两个参数组成~
分类
二胖发现,一款产品并不是所有的尺寸都有,比如下面的两张图,第一款产品的尺寸只有ABC,而第二款产品的尺寸是B-F。
很少有一款产品所有尺寸都有。
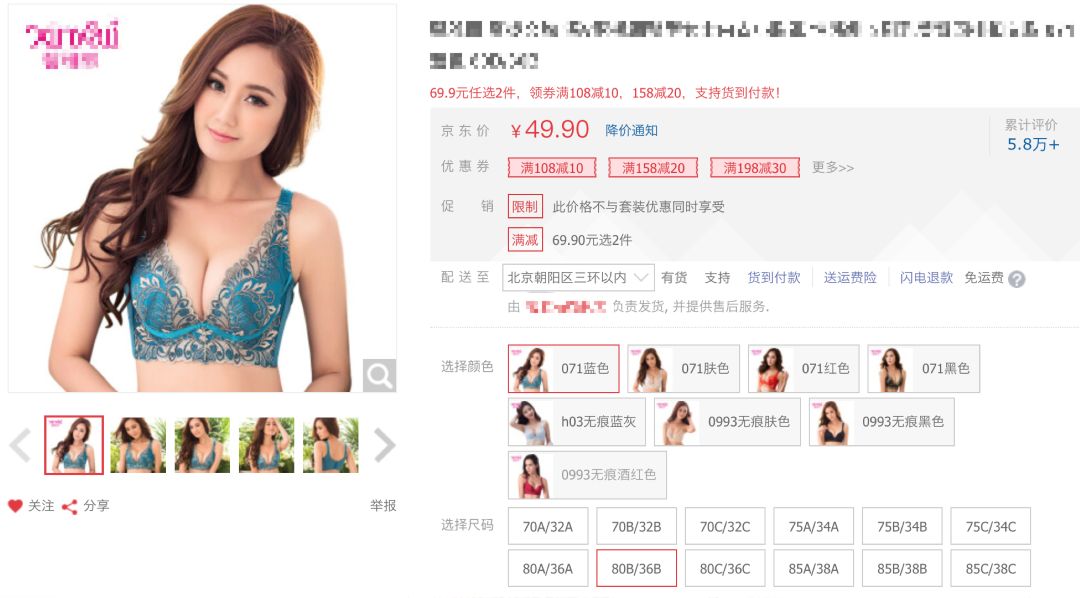
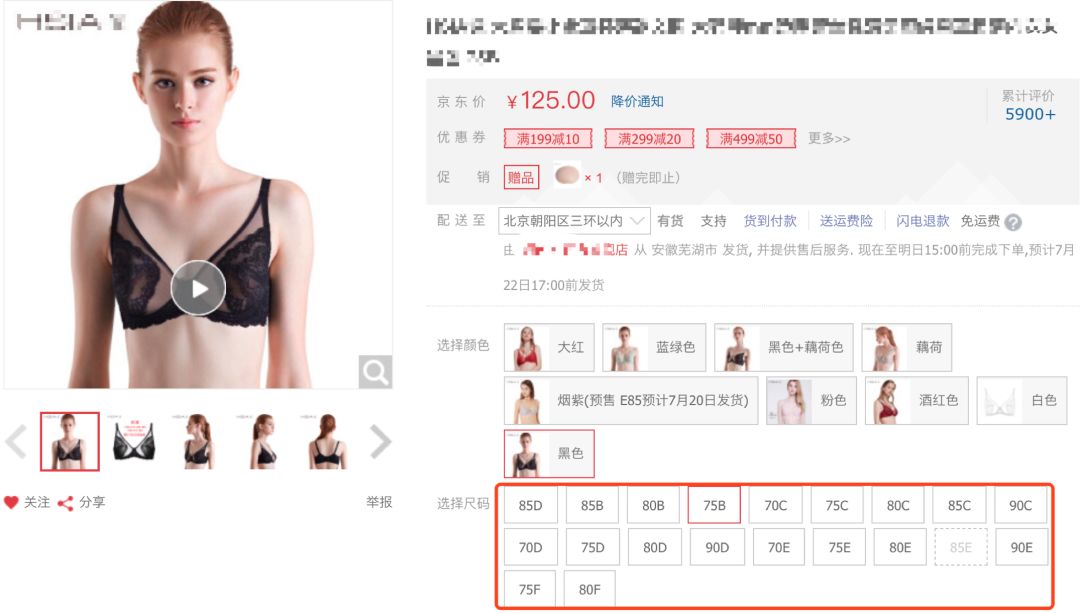
所以,很难仅从一款产品推测出所有人的购买趋势。
这里,二胖选择了把小号(ABC)和大号(B-F)分开讨论,并且每种型号各抓取三个不同的品牌来进行统计。
在这种情况下,数据不一定准确,但是至少能体现出大家的购买趋势。
参数选择
这里我们就选择三个参数来分析,分别是产品的尺寸(你懂的,就是大小),产品的颜色以及用户购买产品的平台。
小号(A-C)
小号指的是仅有ABC尺码的产品,这里统计了3款不同的产品,合计3000条交易记录。
1.尺码
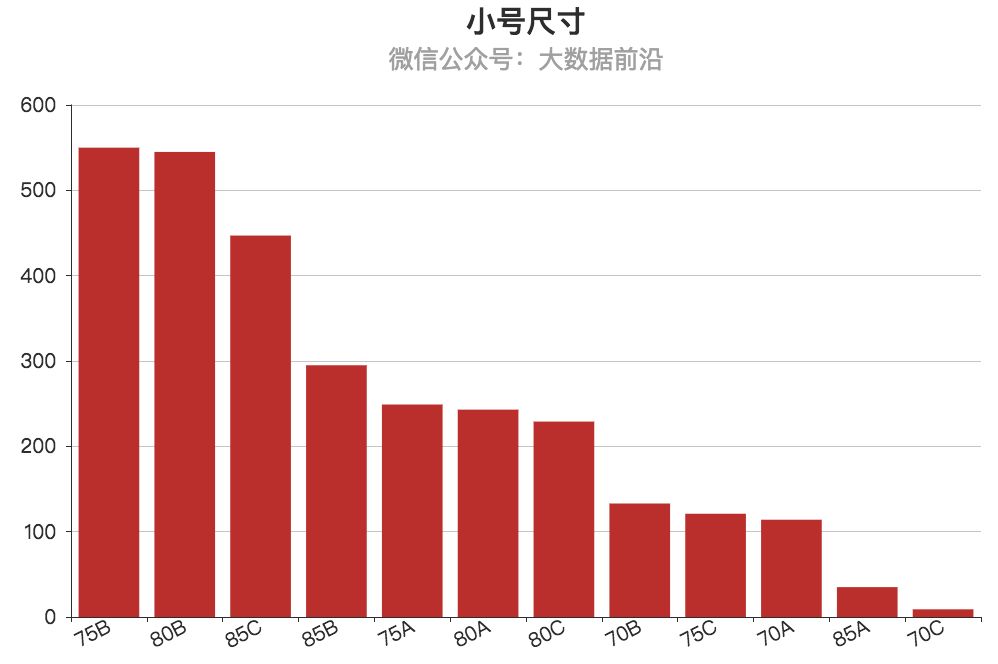
从统计结果来看,小号产品中,75B和80B卖的最好。
2.颜色
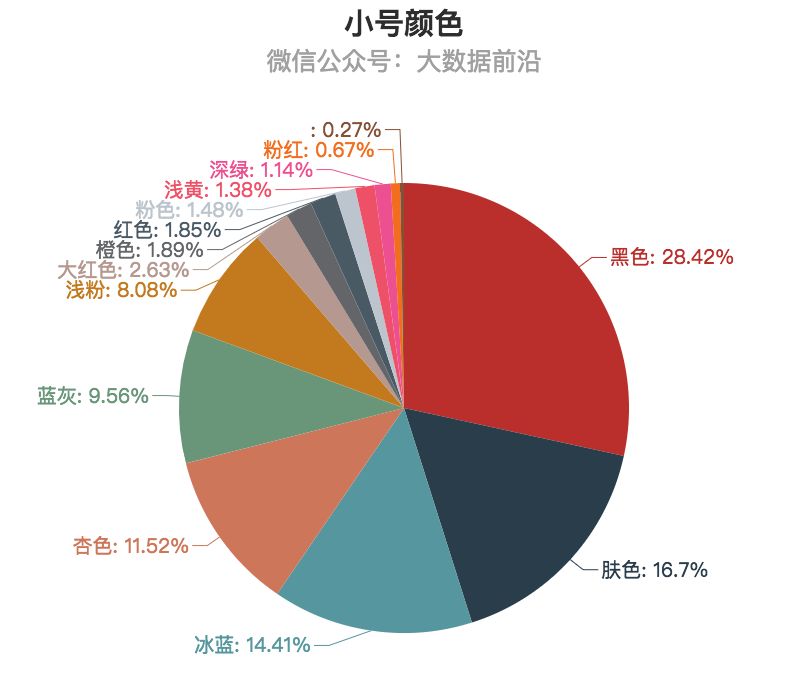
在小号产品中,黑色最受用户青睐,也许是相对比较性感?
3.购物平台
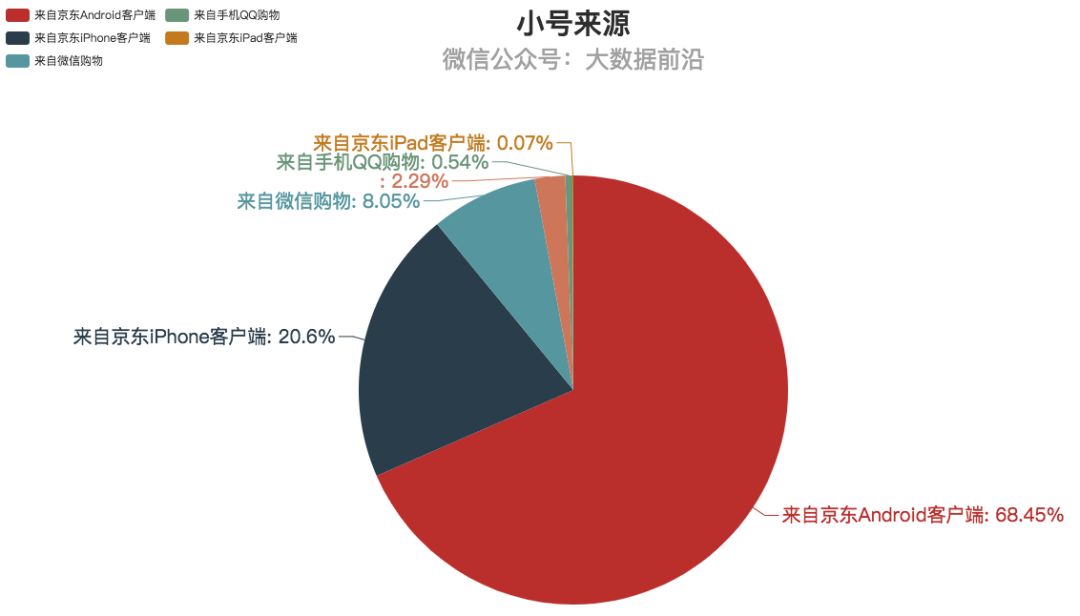
总的来说,还是从京东App购买的用户最多,但也可以看到,有8%的用户是在微信平台上进行交易,这已经是一个不小的数字了。
大号(B-F)
1.尺码
大号指的是尺码在B-F之间的产品,和小号一样,也是统计了3款不同的产品,合计3000条交易记录。
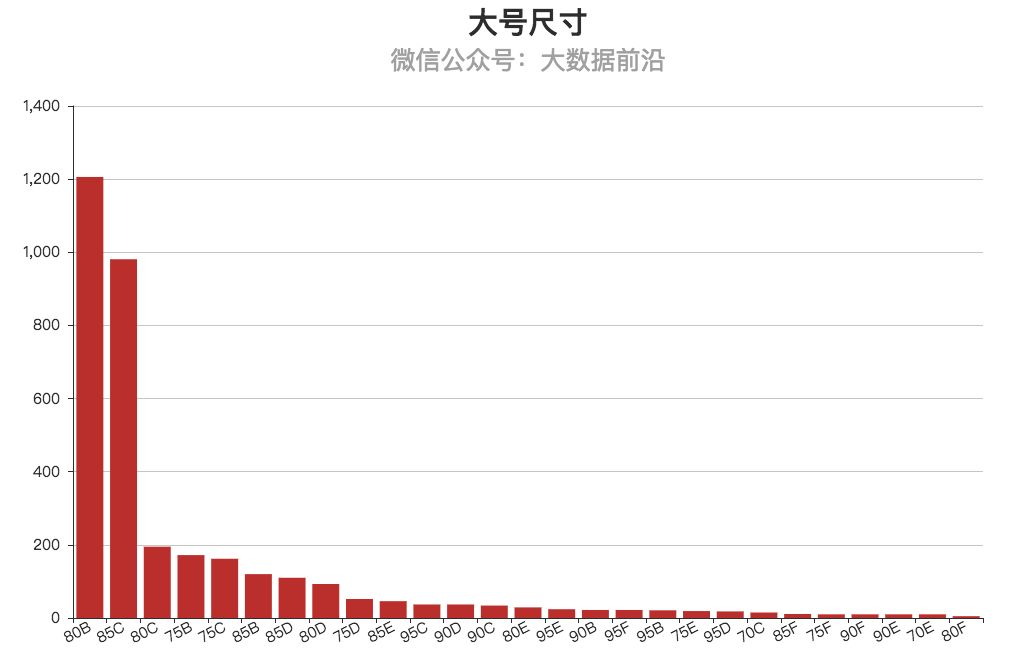
大号产品的尺寸稍微多一些,从B-F都有,不过从大家的购买记录来看,还是B占据了大头,B和C加起来已经超过了三分之二。
2.颜色
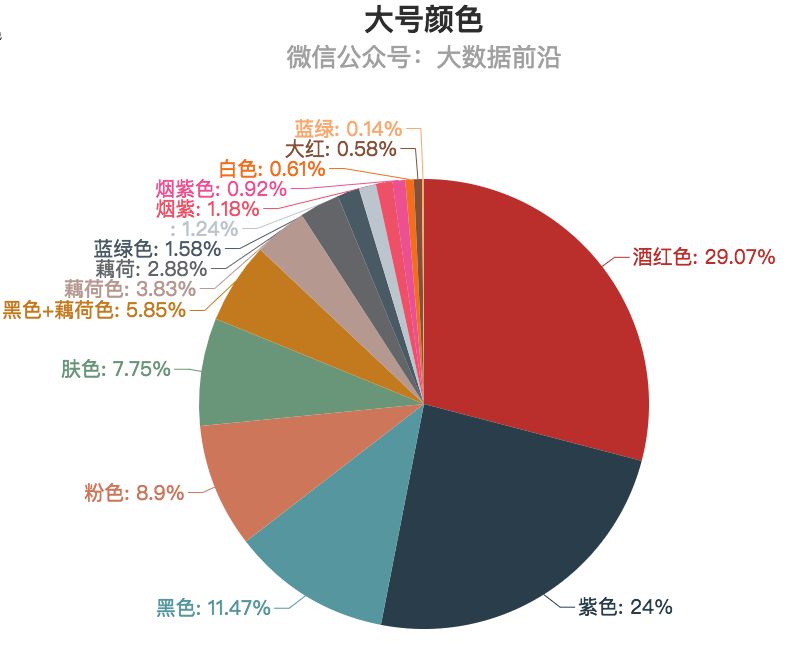
可能是由于具体产品的影响,大号和小号的颜色差别还挺大,大号最受欢迎的颜色是酒红色,其次是紫色,不明觉厉~~
3.购物平台
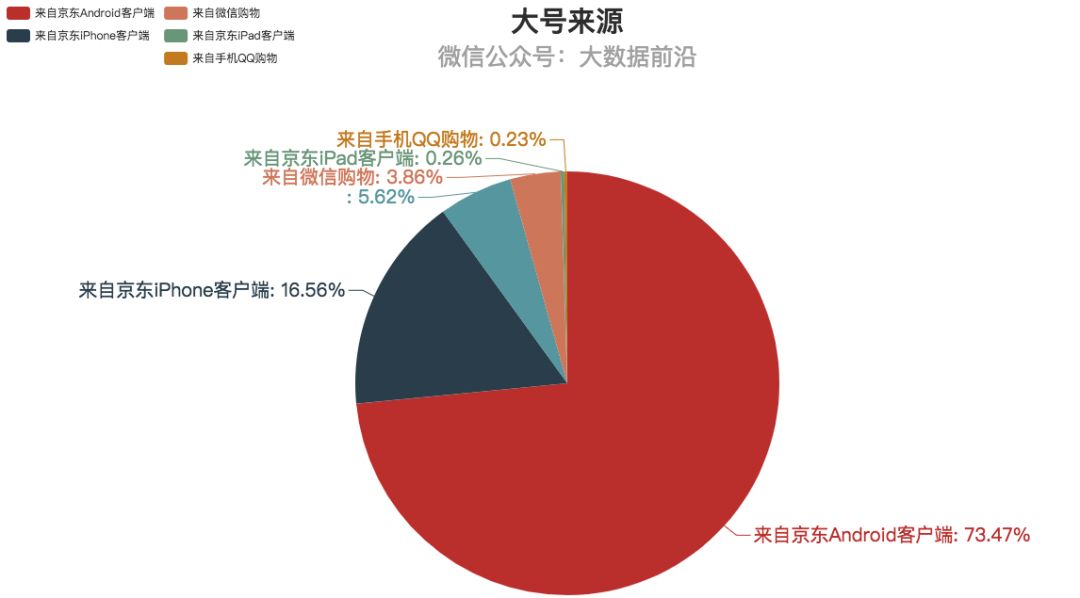
从购买来源上来说,两种型号的产品差别不大,大多数用户都是通过京东App购买的,不过也有细微的差别。
购买小号产品的用户比购买大号产品的用户更喜欢用iphone(大约高了4%)。
文件下载
代码github地址:https://github.com/yangxuanxc/jingdong_crawler
视频地址:https://v.qq.com/x/page/g0732q8orka.html
如对GitHub不熟悉,可前往下面的百度网盘进行下载
百度网盘下载链接: https://pan.baidu.com/s/1KUaYDn4_Vnfl1yaUR-DwrQ
密码: gez5
技术分解
看完了上面的分析,我们来看看是如何将数据抓取下来的。
代码和视频讲解的链接放在了留言区,需要的同学自取~
上次给大家介绍了使用Java抓取微博数据,而这次爬虫使用的是Python的爬虫框架Scrapy。
主要流程代码如下:
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
import json
import math
import time
import re
class BraSpider(scrapy.Spider):
name = 'bra'
headers = {
":authority": "sclub.jd.com",
":method": "GET",
":scheme": "https",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-encoding": "gzip, deflate, br",
"accept-language:": "zh-CN,zh;q=0.9,en;q=0.8",
"cache-control": "max-age=0",
"upgrade-insecure-requests": "1",
"cookie":"t=8444fb486c0aa650928d929717a48022; _tb_token_=e66e31035631e; cookie2=104997325c258947c404278febd993f7",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
}
base_url = "https://sclub.jd.com/comment/productPageComments.action?productId=17209509645&score=0&sortType=5&pageSize=10&page=%d"
def start_requests(self):
for page in range(1,100):
url = self.base_url%page
print(url)
self.headers[':path'] = url
yield Request(url, self.parse,headers = self.headers)
#time.sleep(2)
def parse(self, response):
content = json.loads(response.text)
comments = content['comments']
for comment in comments:
item = {}
item['content'] = comment['content']#评论正文
item['guid'] = comment['guid']#用户id
item['id'] = comment['id']#评论id
item['time'] = comment['referenceTime']#评论时间
item['color'] = self.parse_kuohao(comment['productColor'])#商品颜色
item['size'] = self.parse_kuohao(comment['productSize'])#商品尺码
item['userClientShow'] = comment['userClientShow']#购物渠道
print(item)
yield item
#干掉括号
def parse_kuohao(self,text):
new_text = text
searchObj1 = re.search( r'(.+)', text, re.M|re.I)
searchObj2 = re.search( r'\(.+\)', text, re.M|re.I)
if searchObj1:
text = searchObj1.group().strip()
new_text = text.replace(text,'').strip()
if searchObj2:
text = searchObj2.group().strip()
new_text = text.replace(text,'').strip()
return new_text除了代码,二胖也录制了一个小视频教大家如何运行上面那段代码。
附上视频:



