
 免费 AI IDE
免费 AI IDE
如果没有缓存,当打开一个有大量内容的页面的时候,将会变得十分的卡顿,因为没有缓存,每次打开页面的时候都进行全部加载,而导致页面打开速度变得很慢,给用户的体验也就十分的不愉快了。有了缓存,则会让原本打开很慢的页面变得“秒开”。那么缓存除了能够加速数据的访问外,还有什么作用?本文将为您详细介绍 java 缓存的运放方式、缓存的类别以及缓存会出现的问题。
一、缓存能用来做什么?
大多数人对于缓存的理解就是,当我们打开一个页面或是一个APP,当它们打开的速度很慢的时候,都会想到引入缓存,这样打开就会更快。
从技术这一方面来说,缓存之所以能够提高访问速度,是因为缓存是基于内存去建立的。而内存的读写速度相对于硬盘是快很多的,所以用内存代替硬盘作为读写的介质,自然就会大大提升了访问数据的速度。
使用缓存的过程大致如下:

二、运用方式:预读取和延迟写
除了上述的过程之外,缓存另外两个重要的运用方式:预读取和延迟写。
2.1 预读取
从字面意思来看就是预先读取,实际意义也确实如此。预读取就是提前把将要读取的数据载入,也就是在系统中把硬盘中的一部分数据提前加载到内存中,然后对外提供服务。
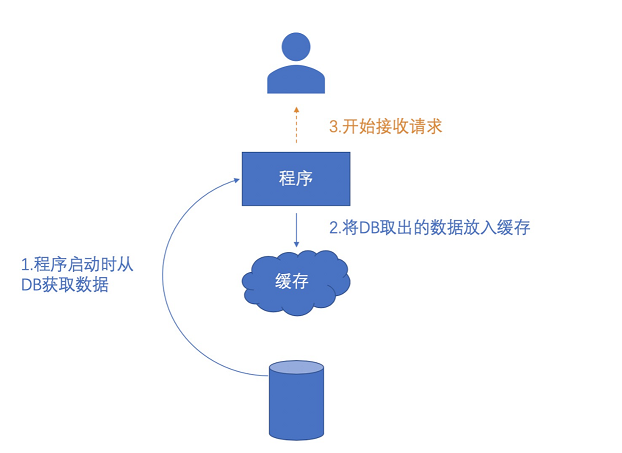
那么这么做的意义是什么?
因为有些系统一旦启动就会有数以万计的请求涌进来,假设让这些请求直接打到数据库上,非常大的可能就是会让数据库的压力剧增,数据库就会被挂掉,而导致无法正常响应。
预读取就是为了解决这样的问题。
2.2 延迟写
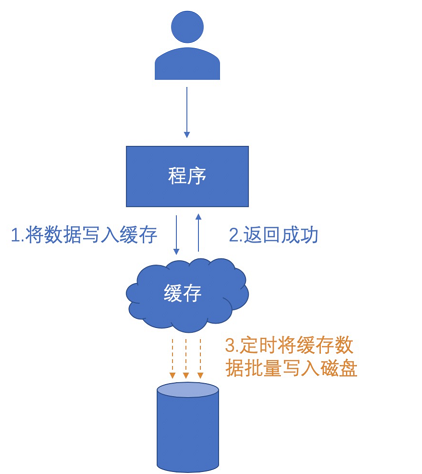
如果说预读取就是在数据出口加一道缓冲区,那么延迟写则是在数据入口加一道缓冲区。
由于数据库的写入速度要比读取速度慢,因此在写入的时候就需要一系列的保证数据正确性的机制。所以,要想提升写入速度,或是分库分表,或是通过缓存加一道缓冲,再一次性批量写入磁盘。引入分库分表的复杂度远大于引入缓存,一般都是优先考虑引入缓存的方案。
这种缓存方案就是延迟写,它是预先将准备写入磁盘或数据库的数据,暂时写入到内存,然后返回成功,再定时分批将内存中的数据写入到磁盘。
三、哪些可以加缓存?
在缓存之前需要考虑我们要缓存的是什么?符合什么样特点的数据才需要加缓存?因为缓存算是一个额外的成本投入,所以加了缓存要体现它的价值。
先引入衡量数据的两个标准:
热点数据:被高频访问,如每秒几十次以上。
静态数据:很少变动,读取要大于写入。
以终端用户为起点,系统所使用的数据库为终点,这其中可以作为缓存设立点大致如下:
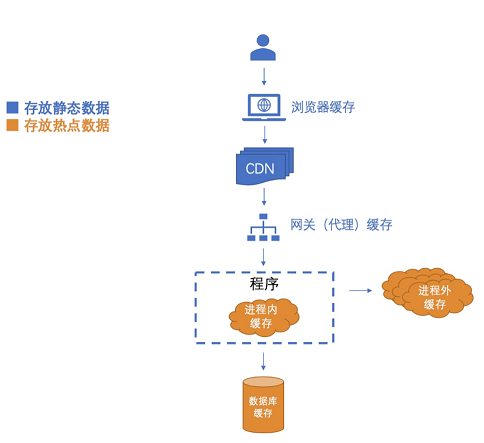
每个设立点都会挡掉一些流量,最终会形成以下的漏斗形效果,以此可以保护后面的系统以及最后的数据库。
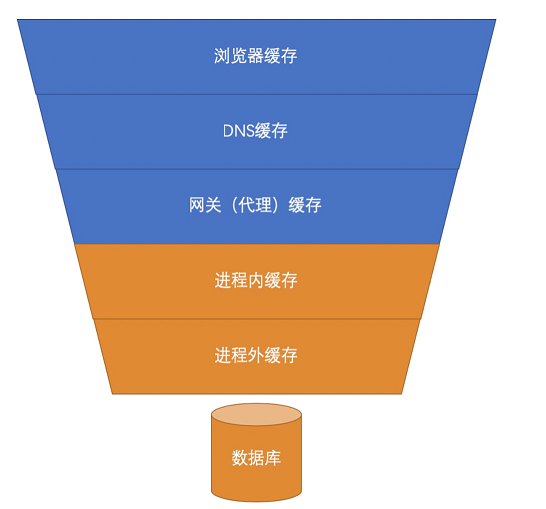
这些设立点就像是红绿灯,如果没有红绿灯就容易发生事故,或是造成交通瘫痪等等。缓存设立点就是防止请求大量涌入,导致无法正常访问。
四、缓存类别
上文已经罗列了缓存的几种类别,接下我们将会对这些缓存类别进行介绍。
4.1 浏览器缓存
浏览器是离用户最近的,可以用来作为缓存的地方,而且借助的是用户的资源,性价比是几种里面最好的,可以让用户分担一些压力。
进入浏览器的开发者工具,有 from cache 、from memory cache 和 from disk cache 的时候,说明数据已经被缓存在用户的终端设备上,在没网的时候也可能访问到一部分的内容就是这个原因。
浏览器会帮助我们完成这个过程,一般适用于图片、 js 和 css等这些资源的缓存。
浏览器缓存的劣势就是我们对它的掌控力比较差,没有发起新的请求的情况下,是无法主动去更新数据。
4.2 CDN缓存
提供CDN服务的服务商,在全国乃至全世界部署了大量的服务节点。我们就可以将数据分发到遍布各地服务器上作为缓存,当用户访问时可以读取就近的服务器上的缓存数据。这样就可以分摊压力和提升了加速效果。
要注意的是,由于节点众多,更新缓存数据会比较慢,一般至少是分钟级别,所以该缓存适用于不经常变动的静态数据。
4.3 网关(代理)缓存
我们经常会在源站前面加上一层网管,目的是为了做一些安全机制或者作为同一分流策略的入口。
在这里设立一个缓存,能够拦下来请求,其背后的源站也是收益很大的,减少了大量的 CPU 运算。常用的网关缓存有 Varnish、Squid、Nginx。
4.4 进程内缓存
一个请求能够到这里来,说明是“业务相关”,需要经过业务逻辑的运算。从这里开始,对缓存的引入成本相对于前三者而言,要大大的增加了,这是因为对缓存与数据库之间的‘数据一致性’要求更高了。
4.5 进程外缓存
这里是大多数程序员所熟悉的地方,就是 Redis 和 Memcached 之类,或者也可以自己单独写一个程序来转存放缓存数据,提供给其他程序远程调用。
4.6 数据库缓存
数据库缓存是数据库的内部机制,一般都会给出设置缓存空间大小的配置来让你进行干预。
最后,磁盘本身也是有缓存的,所以能够让数据平稳地写入到磁盘,可谓是经历了一波三折。
五、缓存可能出现的问题
既然缓存作用如此大,那是不是就越多越好呢?只要速度慢就加缓存来解决?其实不然,缓存既有好的一面,也会有负面的一面。
5.1 缓存雪崩
问题:大量请求并发进入缓存时,可能由于某些原因缓冲效果未能正常执行,即便是在很短的时间内,就会导致请求全部转入数据库,从而造成数据库压力过重。
解决:可以通过“加锁排队”或者“缓存时间增加随机值”来解决此类问题。
5.2 缓存穿透
和缓存雪崩很相似,区别在于穿透会持续更长的时间。这是因为每次的 cache miss 后依然无法从数据源把数据加载到缓存,导致持续产生cache miss。
可以通过“布隆过滤器”或者“缓存空对象”来解决此类问题。
5.3 缓存并发
一个缓存 key 下的数据被同时 set,怎么保证业务的准确性?如果进程内、进程外、数据库三者的缓存一起用的情况下?
使用“先DB再缓存”的方式,并且缓存操作用 delete 而不是 set。
5.4 缓存无底洞
虽然分布式缓存是可以无线横向扩展的,但是,集群下的节点也不是越多越好。缓存也是符合“边际效用递减”规律的。
5.5 缓存淘汰
内存的容量是有限的,如果请求的数据量是大量的,那么根据具体情况进行一定的淘汰策略是必不可少的。例如:LRU、LFU和FIFO等等。
六、总结
本文主要介绍了Java缓存的运用方式的三种思路,Java缓存的类别,在系统中可以设立缓存的几个位置,以及最后总结了 Java 缓存中会遇到的问题。如果想对文章中的具体细节有更多的了解,请关注 w3cschool 或 编程狮APP。



